Statistics, "localised" light sampling, and other "fancy" stuff
I’ve now implemented pretty robust support for statistics in Imagine, both count-based (counters of events) and time-based: having statistics is important in order to know how to optimise your scene and work out where time is being spent from a user’s point-of-view. Imagine has three modes statistics can be set to: Off, Lightweight and Full. Off and Lightweight under-the-hood are the same (although Off doesn’t print to console/write to file the results) and just increments counters of events, like rays fired by type, maximum path length, BSDF evaluations, texture reads, etc. This mode has no measurable overhead (I couldn’t see the difference in a 1 hour render, anyway), although technically the code is doing a few more integer additions. At first I tried using global atomic counters, but these did have a slight overhead (atomic variables can still have contention issues), so in the end I made use of per-render-thread statistics which got added together at the end of the render. Full adds time-based counting to the mix, unfortunately with a slight overhead (~1-3% of total render time depending on how many timers I used and where) as accurately timing lots of events in a fine-grained manner has a small but noticeable overhead, but in a (not-quite-yet in Imagine’s case) production-level renderer, time statistics can be immensely useful (as long as they’re accurate) in identifying bottlenecks / inefficiencies in rendering scenes. The stats aren’t quite as comprehensive as PRMan’s, but they’re more comprehensive than any other commercial renderer I’ve used.
I also added heatmap output support from a render bucket point-of-view, which is just the total time each render bucket took normalised over the entire image which quickly shows you where the majority of the time was spent (see below for an example, where hair rendering takes up the bulk of the time) and a slightly-hacky per-pixel CPU time AOV output.


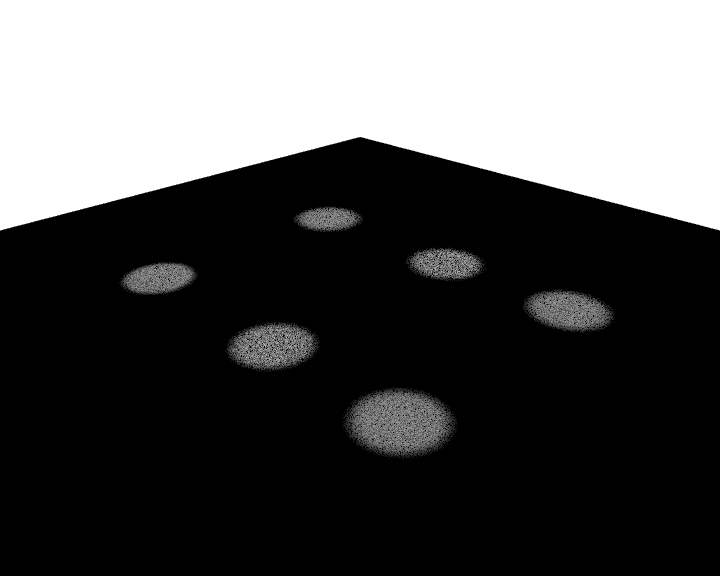
I’ve also been working on “localised” light sampling, where instead of randomly picking lights to sample either uniformly or from a distribution based off a light’s constant total emission, you “localise” the picking of lights to the shading point(s) being shaded/lit - the aim being to ensure you sample lights that will give a greater contribution than lights far away, which can make a tremendous difference when there are thousands of lights in a scene. In Imagine’s case, I’ve done this based on the direction and distance (with a bit extra for spot lights), and implemented a double-stage lookup, where when ray intersections need to be lit by direct lighting, I build up a small (up to 128) per-thread distribution based off approximate radiance of random lights. This then allows discarding of lights which don’t actually contribute any lighting to that particular intersection point. Care has to be taken to balance the distribution pick PDF to ensure lighting doesn’t get biased by this.
While this is more work and therefore more expensive, in that there’s much greater chance that lights being picked are going to contribute lighting to shading points (it doesn’t test occlusion visibility though, so there’s still a chance that the light might be blocked by something), it can reduce noise considerably as the below contrived scene with six spot lights shows. Four samples per-pixel were used, each picking one random light in the first case. Once complex geometry mesh lights (i.e. self-shadowing/occluding) and environment lights come into the picture and there are mixed light types in the scene it doesn’t work as well, but it still gives a huge improvement in certain scenes.

I’ve also added checkpoint support (resuming renders), by saving the sample count per-pixel to the output EXR which can then be read in again and resumed, along with a bit of metadata. I’ve also reduced memory usage a bit more and started work on PrimVar support.