Over the past year I’ve been working on (and to a much greater extent optimising) an image texture cache system for Imagine.
Imagine has had some form of reading planar (entire) images since very early on, but other than a slightly hacky integration of OpenImageIO (but that did work efficiently) into Imagine just to test things, it hasn’t had proper integrated support for reading (and more importantly paging) partial images lazily on-demand. This ability is essential for a production level renderer in VFX, as the size and number of image textures used in VFX for rendering is pretty extreme.
I could have just integrated OpenImageIO properly into Imagine, but there were a few reasons I didn’t want to do this: First and foremost, I wanted to write my own and experiment with different ways of handling concurrency, scalability as well as eviction. Second, I already had my own file readers / writers and didn’t like some of OIIO’s dependencies. Further reasons were that OIIO comes with a fair bit of baggage which at least in my use-case for texture reading, I didn’t care that much about: in particular rather bloated data structures in some cases (partly due to Field3D support requiring matrices). It also had some limitations: didn’t support constant tiles, although in fairness there aren’t any open file formats that support this, although I’d like to investigate creating a file format at some point - which can make a huge difference in terms of File I/O bandwidth (which is a very important bottleneck for high-end VFX rendering), it doesn’t natively support texture atlassing (e.g. UDIMs) and I was also not completely convinced by its efficiency or scalability, although it definitely is a capable and production-proven library. I also wanted to experiment with adding new features like on-the-fly compression of tile data, and doing this in a clean and minimal code-base would be much easier.
Imagine already had file readers, but they only supported reading planar images into image buffer classes, so the first step was to provide the ability for a file reader to describe the metadata of an image file, and fill in the details, including resolution, number of channels, data type and mipmap levels.
In terms of general storage of image textures, I created something that’s essentially similar to OpenImageIO’s overall design, whereby there are two main items stored in the cache: image items, which represent the actual image file metadata, and image tiles, which represent the pixel data of the images themselves, broken into small tiles. However I wanted to try slightly different algorithms to what OpenImageIO uses for tile eviction, as I had the suspicion the method it uses (mark and sweep iterator over entire tile cache) wasn’t the best approach from a speed and scalability perspective. One of the ideas I had in mind was not actually removing any tile items at all at eviction time, but only freeing the pixel data itself. This would use more overall infrastructure memory (excluding pixel data), but it should reduce the need to lock the entire tile cache very slightly, which hopefully would help scalability and performance. Given that classes and structs representing texture items and texture tiles would never be freed at tile eviction for paging, it was therefore extremely important that they be as memory efficient as possible.
I made a conscious decision to not separate different channel images based on tiles requested based on the channels requested - that is, if an RGBA image was loaded, but only the A channel was requested, I’d still load all four channels into memory instead of partitioning each tile and having an extra dimension to have to cope with for the tile hashes. This was partly to keep things simpler, but also to constrain the number of tiles given I wanted to not have to free the tile items at all when paging, only freeing the pixel data. It would mean however, that in certain situations like the example given above, memory usage would be higher than needed. However, as is generally done in high-end VFX, the solution here is to make sure each texture image just contains one set of channels, so the above example would have two textures, one for the RGB channels and a separate one for the A channel.
I also made a decision to not use lazy texture loading for HDRI environment maps, but to keep those separate, partly because you’re effectively point-sampling them anyway (definitely at construction time to build the CDFs), but also to keep texture requests down for this type of illumination.
I also wanted to be able to categorise images based on purpose, both for allowing different caching / eviction strategies for different types and to allow different types of filtering to be done on them: there are some situations like for alpha/presence maps and layering mask/mix maps that it’s generally better to err on the side of less filtering, even at the expense of possible aliasing.
To begin with I started with just the bare basics as I wanted to investigate and experiment with different ways of doing things to see the effects they would have. As a starting point I initially just had a single mutex around each map collection, so that I could see what the extreme worst-case scenario was.
Imagine was using ray differentials to calculate texture filter regions and thus the mipmap levels to pull in of the textures, and doing trilinear filtering to combine mipmap levels.
Tests even with just a single plane polygon in the scene with one texture were as expected pretty abysmal, with CPU utilisation on a 16 core / 2 socket system hovering around 300% (instead of the ideal of 1600%).
I implemented per-thread microcaches that stored LRU arrays of pairs of both the texture items and their hashes and tile items and their hashes, which was used to lookup textures before going to the main cache and in this contrived scenario, other than for the first few buckets where all threads were initially opening file and reading images, CPU utilisation went up to the expected 1600%, fully utilising the available cores.
Testing with other simple objects added to the scene with the same texture (so that there were now indirect rays being fired in an incoherent fashion) could scale to a degree if I increased the microcache sizes, but this wasn’t going to be a good approach, as the single mutexes around the individual map containers were clearly the bottleneck.
So I needed to come up with a solution which would scale well with many threads. In the end I settled on writing my own map container wrapper similar to Java’s ConcurrentHashMap (which is also similar to what OIIO uses, and how Linux’s hashed spinlocks work), which splits the map into different “bins” (although I called my version “shards” which is more in mapping to the database partitioning technique). Each “shard” contains its own isolated map and mutex, and the shard to use for lookup and inserting values is chosen by using the modulus of the hash value for the key, based on the number of shards. It’s then possible to lock just this shard and lookup within its individual map to find / set the value as required, while other concurrent requests from other threads will have no contention, so long as they map to different shards. If they do map to the same shard, then there will be a certain amount of contention. So it’s extremely important to have a very good hash function which distributes well over the domain space. In my case, after an awful lot of trial and error and playing around with the avalanche effect of hashes for tiles, I came up with hashes which seem to work quite well: I used Austin Appleby’s MurmurHash3 for hashing the filename, generating a 32-bit integer, which allows lookups of the texture item itself.
For tile items, I ended up using a 64-bit integer of the 32-bit texture item hash shifted 32-bits to the left, being added to by the mipmap level shifted 24-bits to the left, then the tileY coordinate shifted 14-bits to the left with the final tileX coordinate unshifted.
Another very important factor which was important is mixing the hash used to lookup the shard so that it doesn’t have the same correlation within the shard’s hash map, which can severely affect the efficiency and load factor of hash maps within each shard.
With this implementation, scaleability was perfect on 16 threads with these simple scenes, so I then attempted to stress-test it with more complex test scenes and finally as close to a production level scene as I could fabricate texture-wise.
I tested initial scalability of the locking by using “virtual” image texture readers which just generated texture colours procedurally (tiled based) so as not to be limited by disk speed or OS-level disk caching.
Tests with the extreme worse case scenario (just a single mutex around the containers - and using the less-than-ideal std::map<> to begin with for lookup structures) were understandably atrociously bad, although interestingly scaling on Linux was much better than on OS X, probably due to Linux’s Futexes.
Scalability with sharded maps was much better on OS X, and noticeably better on Linux, scaling close to linearly with 32 shards for both maps. Changing the underlying map type to std::unordered_map (hashmap) reduced lookup time by around 25%, which was not as much as I had hoped. I experimented with setting the initial bucket count and max load factor for the maps and this reduced lookup time by around 10% again, and at this point I was slightly worried that my hashes weren’t as well distributed as I thought - so I thought this would be a good time to both check the distribution of the hashmaps and see if the strategy of not deleting items from the maps gave any benefit. Without controlling the load factor and initial bucket count, once paging started happening, not deleting items seemed to give a slight speedup - possibly due to the fact tombstones didn’t need to be used to mark items as deleted. However when optimising the initial load factor and bucket count, the difference was negligible - probably due to hashes mapping very nicely to open buckets with very few collisions happening. However the ability to not delete tile items did mean that in the texture stats I was able to very accurately track unique texture data read during paging, which is quite useful, and I kept this as an option.
I experimented at this point with increasing the microcache sizes a bit (to 16 entries per thread for both), and for simple scenes with less than 60 textures this made a noticeable difference (especially with paging enabled, as it meant if an item was in a microcache it was recently used so it shouldn’t be evicted), but once each ray hit was evaluating more than 10 textures for layered materials, these microcaches became barely useful due to almost random thrashing between vertices per path. I have some ideas for trying to use more tree-like data structures for them in order to take advantage of ray-tree coherence, but the best approach here would just be full-on deferred ray batching / sorting, so I’m not convinced it’s going to be worth it.
At this point without having to page textures to fit in a particular memory limit, my texture cache was faster than OpenImageIO for pretty much identical numbers of texture evaluations, but with aggressive paging turned on OpenImageIO was noticeably faster. Looking at the stats between the two, it was obvious that my naive eviction method was causing an awful lot of duplicate reads (still using virtual file readers, so no disk access was taking place, only memory allocations and procedural textures). I decided to just copy OpenImageIO’s clever method of marking a tile as recently used with an atomic variable, allowing a very cheap compare-and-swap to be done, allowing skipping recently-used tiles very accurately and efficiently, although with a slightly less cumbersome mark-and-sweep process. This change made a huge amount of difference, with my texture cache now being ~5-10% faster than OpenImageIO. I also experimented with over-evicting based on a ratio to prevent continual locking: if a request for a new image needed 2KB of data, I’d actually free more than that, so as to do more work within the one lock event meaning it would be more likely the next request for a new texture would not need to lock as well to evict - this made a noticeable improvement (after experimentation I settled on doubling the target eviction size).
I then decided to move to proper tiled based image textures, testing both TIFF (briefly) and OpenEXR. I noticed immediately with OpenEXR that using the worker thread calling OpenEXR to read images (i.e. with the threadpool size set to 0) had severe contention issues, caused by redundant locking in IlmBase’s ThreadPool class. Larry Gritz had also spotted this issue previously and had a fix for it on GitHub which allowed EXR reading with worker threads to scale a lot better. Along the way of testing with bigger and bigger scenes I had to fix several issues with ray differentials not propagating correctly causing incorrect point-sampling of the lowest level mipmaps, which obviously slows things down to a halt. In the end for some edge cases I had to build in texture filtering based on approximate ray-width as a backup for when ray differentials failed (due to incorrect/inconsistent UVs or missing UVs on meshes).
I then decided to scale things up to an extreme test to stress test the cache: I tested with a large cornell-box style scene containing four production-scale hero objects - many different components with different materials, all with UDIMed textures with varying numbers of layers (one to three, controlled with mask textures controlling mixes), with diffuse, specular colour, specular roughness, clearcoat reflection and bump textures being utilised for most (but not all) materials. The floor and the walls of the Cornell box also had diffuse textures of 10x10 tiles of UDIMs (so each plane other than the ceiling consisted of 100 texture files).
The total number of image texture files was 898, and I made use of OpenEXR format tiled mipmaps of 16-bit half format at 8K, the tile size being 32x32. Total size on disk for all textures was over 320 GB.
I tested with path length set to 6, so there would be a large amount of incoherent texture accesses.
Testing this scene showed it worked very well, and was consistently slightly faster than OIIO - this is probably partly due to less locking that I do in general, but probably also because my texture cache has full integrated support for UDIMs, so can batch up requests to adjacent tiles on UDIM borders and when filtering to reduce locking even more.
I experimented with adding support for compressing pixel tile data in memory using LZ4 - the idea being that for constant tiles (which no open standard tiled file format supports at present, so there’s no way to detect them up front) it might be a way to detect these on-the-fly with a tiny bit of overhead. Testing with simple textures worked well, and if the compression ratio was excellent it was obvious it was a constant tile, and I could mark it as such and not bother evicting it, which brought a slight speed-up. If the compression ratio was just good, there was some constant data in the tile, and it meant I could fit more in memory without going back to disk when paging. However, with real-world textures painted in Mari it didn’t work as well, as outside the UV’d area Mari tends to distort texture detail instead of leaving it black, so there’s still texture detail there taking up space. One situation where compressing did still provide benefits with real-world textures was with layer masks texture maps used for mixing / isolation, which are generally less detailed anyway - it was possible to often detect constant tiles and even if there weren’t entire constant tiles still compress image data usefully within tiles.
So I now have a very fast, efficient and scalable image texture cache - I still think there could be better texture formats than OpenEXR which unfortunately has become the standard for textures at VFX level but is seemingly somewhat abandoned: OpenEXR’s threading is really bad, and the use of threadpools doesn’t really make sense for reading multiple random tiles per random mipmap level in parallel in a path tracer - it’s possible with coherent access using threadpools is still a win for rendering (it definitely does make sense to use threadpools to speed up reading a single large entire image for use in image viewers and compositors, and for writing images), but I think it makes sense that a file format for rendering be completely stateless, with metadata decoded once, and then any number of threads be able to read/uncompress at will without dependencies / state controls - obviously depending on how the image is compressed there may be problems here, but a balance needs to be found. In addition OpenEXR doesn’t support 8-bit or 16-bit integer formats which can be very efficient for certain types of data (masks / isolation maps), neither does it support constant tiles or instanced tiles. So I’m tempted to try creating a texture format just for rendering, optimised for extremely fast random access.
I’ve just finished implementing the first pass of the ability to record events that happen during light transport, and visualise them in Imagine’s OpenGL viewer. I’d been having issues with light sampling issues with complex light setups with many lights, and just looking at the code and debugging what was going on from within gdb wasn’t really getting me anywhere.
So I decided that as Imagine has a GUI (in non-embedded mode, anyway), it would be fairly easy to record events like path vertices, light sample positions, etc, during light transport and then later display them in the viewer. I ended up creating a separate DebugRenderer integrator for this, which I’m not completely happy with as it means code duplication in order to replicate light transport and light sampling, but integrating this event recording (at a fine grained level) brought with it some time overheads - definitely when recording events, as expected, but it was also even slightly noticeable when it was turned off in the light sampling code, presumably due to extra branching - but more importantly it complicated the existing code quite a bit, so for the moment I’m going to keep it like this.
It’s allowed me to very easily identify issues with spherical analytical light sampling in Imagine, as well identifying some other light sampling issues, and with some future improvements to support volume scattering events as well as better view-time filtering (to allow constraining the preview of these events to useful subsections), it should be better still.
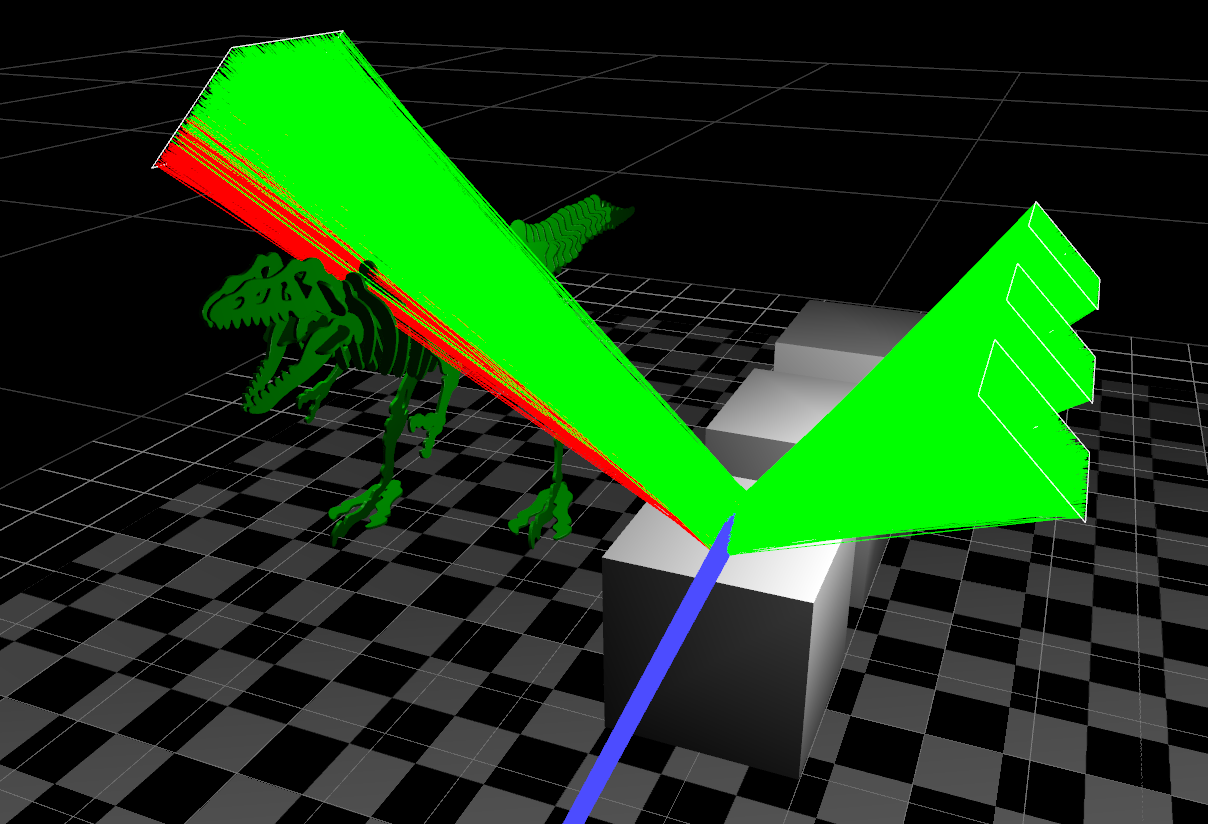
The below images show the rendered scene and the visualisation of a sub-set of rays hitting the top of a cube for the first hit event from the camera: blue lines are camera rays, green lines are successful next event estimation rays which found a light and red lines show next event estimation rays which were occluded.
It can also show un-sample-able light samples (back-facing), secondary bounce rays (tagged/coloured diffuse, glossy or specular) and exit rays which didn’t hit anything in the scene.
I’ve now implemented pretty robust support for statistics in Imagine, both count-based (counters of events) and time-based: having statistics is important in order to know how to optimise your scene and work out where time is being spent from a user’s point-of-view. Imagine has three modes statistics can be set to: Off, Lightweight and Full.
Off and Lightweight under-the-hood are the same (although Off doesn’t print to console/write to file the results) and just increments counters of events, like rays fired by type, maximum path length, BSDF evaluations, texture reads, etc. This mode has no measurable overhead (I couldn’t see the difference in a 1 hour render, anyway), although technically the code is doing a few more integer additions. At first I tried using global atomic counters, but these did have a slight overhead (atomic variables can still have contention issues), so in the end I made use of per-render-thread statistics which got added together at the end of the render.
Full adds time-based counting to the mix, unfortunately with a slight overhead (~1-3% of total render time depending on how many timers I used and where) as accurately timing lots of events in a fine-grained manner has a small but noticeable overhead, but in a (not-quite-yet in Imagine’s case) production-level renderer, time statistics can be immensely useful (as long as they’re accurate) in identifying bottlenecks / inefficiencies in rendering scenes. The stats aren’t quite as comprehensive as PRMan’s, but they’re more comprehensive than any other commercial renderer I’ve used.
I also added heatmap output support from a render bucket point-of-view, which is just the total time each render bucket took normalised over the entire image which quickly shows you where the majority of the time was spent (see below for an example, where hair rendering takes up the bulk of the time) and a slightly-hacky per-pixel CPU time AOV output.
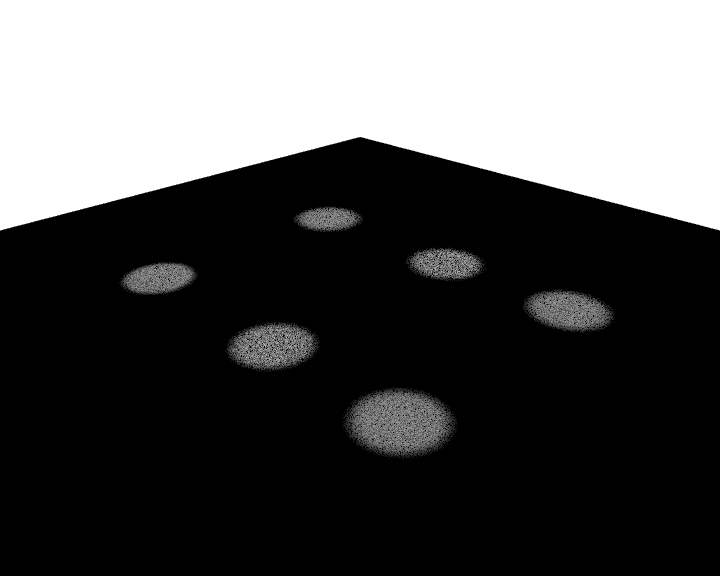
I’ve also been working on “localised” light sampling, where instead of randomly picking lights to sample either uniformly or from a distribution based off a light’s constant total emission, you “localise” the picking of lights to the shading point(s) being shaded/lit - the aim being to ensure you sample lights that will give a greater contribution than lights far away, which can make a tremendous difference when there are thousands of lights in a scene. In Imagine’s case, I’ve done this based on the direction and distance (with a bit extra for spot lights), and implemented a double-stage lookup, where when ray intersections need to be lit by direct lighting, I build up a small (up to 128) per-thread distribution based off approximate radiance of random lights. This then allows discarding of lights which don’t actually contribute any lighting to that particular intersection point. Care has to be taken to balance the distribution pick PDF to ensure lighting doesn’t get biased by this.
While this is more work and therefore more expensive, in that there’s much greater chance that lights being picked are going to contribute lighting to shading points (it doesn’t test occlusion visibility though, so there’s still a chance that the light might be blocked by something), it can reduce noise considerably as the below contrived scene with six spot lights shows. Four samples per-pixel were used, each picking one random light in the first case. Once complex geometry mesh lights (i.e. self-shadowing/occluding) and environment lights come into the picture and there are mixed light types in the scene it doesn’t work as well, but it still gives a huge improvement in certain scenes.
I’ve also added checkpoint support (resuming renders), by saving the sample count per-pixel to the output EXR which can then be read in again and resumed, along with a bit of metadata.
I’ve also reduced memory usage a bit more and started work on PrimVar support.
I did some prototyping of two different shading implementations which allow vastly more flexible shading than Imagine’s previous baked-BSDF approach. The two different methods I tested really only varied in how the memory for the dynamic BSDF components was allocated and used - both methods built the BSDF components after each geometry intersection (for non-shadow rays - in my final implementation it’s also performed when Transparent shadows are enabled), either from constant values or textures. The first test method was using a memory arena to allocate the samples, and the second was allocating the memory on the stack within the integrator loops.
Fairly comprehensive benchmarking - using a worst-case scenario: allocating lots of different BSDFs all driven from image textures, and all controlled by quite convoluted and expensive branching logic - showed that between the two methods, in terms of speed, there was practically no difference. However, there was (as I expected) an overhead to doing this compared to the baked BSDF approach - generally around 4-9% overhead total render time. The extreme end of this I’m putting down to image texture evaluations (all images in the tests were memory-resident, so with texture paging and displacement the overhead could be even higher), and the lower end is probably the additional branching for controlling the BSDF creation now being called for every ray bounce instead of just once. Because of this, and the fact that there didn’t seem to be any overhead in just having the stack based dynamic BSDF components in the integrator loops if I didn’t use them, I decided to use this second approach which allowed me to still use the baked BSDF approach if the material definition was simple enough to allow it. This allows great flexibility but at the cost of some code complexity, but I think that’s a worthwhile trade-off.
So now any float/Col3f material parameter can be driven by textures, and a decision is made per-material at pre-render time whether complex shading is needed on a per-material basis. If not, the material will pre-bake the BSDF as previously, and within the integrators, this baked BSDF is returned by the material shade() function and used.
If complex shading is needed, then the material can make use of the pointer to the stack-allocated BSDF memory which is passed in to the shade() function, allocate BSDF components as required using this memory and then return this pointer to the integrators. The base infrastructure is now in place for node-based shading networks - the GUI side of things for that is the main work required to complete this.
Based on this new functionality, I implemented a MixMaterial ability to mix or binary-switch materials based on a texture.
I also added UDIM texture atlas support with lazy on-demand reading of textures based on the UV coordinates.
Since the last update, I’ve thoroughly refactored Imagine’s image texture and file-reading infrastructure to now support Image textures at native bit depths (except for 16-bit uint support) instead of always converting them to floats as I did previously. I’ve basically reversed the way image loading and texture creation work - previously, image textures were always full float and the image classes were filled by the file readers - now, image classes are created at the most suitable or requested bit depth and interpretation (for single channel images) by the file readers, and suitable image texture classes are created based on these resultant images, which then do any relevant conversion in the texture lookup to return full float values for the integrators / BSDFs: for 8-bit uchar textures, a LUT is used to convert and linearise the values, so speed is not an issue, but for half float, casts have to be done, and unfortunately there’s a small (but noticeable) overhead here, despite twice as many fitting into cachelines. I’ve tried doing any filtering / interpolation for the lookup before converting to full float, and then converting only a single half to a float afterwards, and this helps, but this isn’t possible for HDR images used for environment lighting as the values are often quite high and can be near the limit of half, meaning you can’t average them at that precision. But regardless, this change brings a huge reduction in memory allocation for textures, and it’d now be fairly easy to add texture paging to my texture caching infrastructure.
I’ve also finally made my DistributedPath integrator usable - I’ve been trying to duplicate how Arnold splits diffuse and glossy ray bounces for over a year now, and thanks to some diagrams in its documentation, it looked like they branch at every bounce, which was how I wrote my integrator. Doing this however resulted in a stupid amount of final rays that was ridiculously slow, and also made generating decent samples very difficult and expensive (pre-generating and re-using might have been an option). After playing with Arnold over the last six months and benchmarking it with various sample and depth settings, I’m very certain now that it only splits rays on the first bounce. So with this modification, my DistributedPath integrator is now very usable, and for scenes where geometry aliasing isn’t an issue and no depth-of-field or motion blur is required, can speed up rendering to a particular noise level fairly significantly compared to pure path tracing: it’s helpful when there’s lots of indirect illumination, where the diffuse split multiplier can really help to reduce noise. However, you generally need to increase the number of light samples as well to compensate for the reduced number of camera samples sent out.
I’m currently in the middle of implementing a new and much more flexible shading system - Imagine’s current one is pretty limited and basic, and basically just bakes down BSDF components to a container BSDF at render start, which is then always fixed for that material. This works very well (in terms of shading speed) for simple shading and non-varying mixes of materials, but makes more complex mixes and blends which are controlled by textures very difficult to code, sample and control, and also makes medium IOR transitions very complicated. I’m prototyping two different methods here to see what the overheads / limitations of each are.
In terms of future work, the task after the shading change is to seriously reduce Imagine’s geometry memory footprint, in order to make it more competitive with other renderers. Thanks to Imagine’s origin as a sandbox for learning OpenGL and 3D programming, its native GeometryInstance representation is very inefficient for source geometry, and the baked geometry (tessellated version of source geometry) representation is also pretty inefficient, due to OpenGL’s requirement that you can only access vertex attributes uniformly, so triangle points, normals and uvs pretty much need to be gathered, leading to up to three times as many points, normals and uvs than the source geometry has. I’ve had a TriangleGeometryInstance for a while, which I used in order to be able to load the Lucy Stanford model on my laptop which stores pure triangles very efficiently (and doesn’t do any OpenGL drawing), but I need to support polygons and Sub-ds correctly efficiently, so quite a bit of work is needed. I’d also like to look into changing the indexing size for geometry, so that for meshes with less than 65,535 vertices, I can index them with ushorts, instead of wasting space using uints - for low LOD representations of geometry, this might be quite useful.
I’ve spent a bit more time both getting some decent volumetrics source data (via Mantaflow for the fluid simulations and better self-created procedural clouds for the images below) and improving Imagine’s Volumetrics rendering capabilities.
Below are two animations rendered of smoke fluid simulations:
I’ve added importance sampling (not MIS yet - currently there’s a separate integrator for anything with volumetrics in it) of mediums, so noise is reduced a bit, and I’ve optimised several things - calculating the transmission integration through the medium for lighting is now done with double the step distance than Camera and other GI rays use (I could probably do the same for diffuse GI rays in the future), and I’ve added data window extents to my voxelbuffer format, both of which together give significant speedups (the latter especially with trilinear filtering and sparse volume extent).
I’ve also added initial emission support, but the results are currently pretty noisy.
I’ve now got scene-wide homogeneous single-scattering and multiple-scattering of heterogeneous volumes rendering in Imagine.
I’m not doing importance sampling yet, so there’s room for improvement there, and I’m not taking possible emission into account yet - when I do this I might try and get a black body shader working for the emission values.
The above image is a procedural pyroclastic cloud - for the moment I’m not going to spend too much time modelling volumes, as that’s quite a task in itself, but I’ve implemented a dense grid and at some point, I’ll try and implement a sparse grid for better memory-efficiency and storage. I could have used Field3D’s versions, but the dense version is trivially simple anyway, and ignoring memory limits and paging in the sparse version, I don’t foresee that being that difficult either, plus the dependency on HDF5 is more trouble than it’s worth.
I was tempted to try to get OpenVDB integrated, but the Boost and Intel TBB dependencies put me off for the moment, but it seems a nice solution.
Above is a bound single-scattering medium in a Cornell Box, with the cliché spotlight.
For scene-wide mediums, there’s an interesting limitation which in hindsight is obvious, but I hadn’t thought of before: image-based (or environment) lighting doesn’t really work. It definitely doesn’t work when you set the light distance to infinity or large values, and while it’s usable to a limited extent at much closer values, it’s not really practical. So I’m not really sure how useful scene-wide mediums are in practice - in production, they seem to be mainly used for god-rays anyway, so…
I’ve implemented Curve primitive ray intersection in Imagine based off Koji Nakamaru and Yoshio Ohno’s 2002 paper “Ray Tracing For Curves Primitive”. Basically, it involves projecting each curve’s ControlPoint positions into orthographic ray-space, so that the main intersection test can be done as a curve width test in two dimensions down the ray, and then the depth t-test can be worked out.
For straight curve primitives, this is sufficient, but for actual curves with any curvature down the length, splitting the projected curve recursively and performing the intersection test on these split curves is necessary. The recursion level needed to ensure accurate intersection depends on the curvature of each curve.
This recursive splitting obviously has an effect on the performance of the algorithm, so while intersecting straight curves is fairly fast, for a curve that curves gently at around 45 degrees from the root to the tip, a recursive splitting depth of six is needed, which results in 32 recursive splits, and a total of 64 intersections on both the original curve and the recursively split curves.
Which is unfortunate, as to some extent it makes rendering non-straight curves unpractical for reasonable levels (+100,000) of curves.
For the moment, I’m setting the resultant geometric and shader normals from any intersection as facing back along the original camera ray, so that the normal always faces the camera. This is sufficient for very thin curves.
I’ve also implemented a set of Hair BSDFs for Diffuse and Specular, based on the 1989 Kajiya and Kay paper, which is commonly used. This is optimised for very thin curves, with no effective normal change across the curve, but with a tangent value which can be calculated from the intersection position on the ray.
For the moment, I’m storing curves in an acceleration structure, which works well for very short curves or longer curves which are axis-aligned, but for anything else (long curves going diagonally across dimensions) is bordering on ineffectual, as the resulting axis-aligned boundary boxes for each curve are extraordinarily large, with multiple curves often overlapping each other. I had hoped that spatial partitioning (with curve clipping to boundary boxes) would improve this considerably (it’s fairly useful for triangles), but the improvement for using curve clipping with spatial partitioning is not anywhere near as good as I would have hoped (it provides a slight intersection speedup though compared to object partitioning).
So for longer hairs, I’m going to have to think about how to speed this up considerably, as currently rendering long curved curves is orders of magnitude more expensive than I would have liked. It’s also going to either involve work to model and simulate hair strand interaction more, or import curves from elsewhere, as the method of generating hairs around meshes (importance sampling positions on each triangle for the root positions) and giving a random tilt or curve only really works with fur-type curves.
I’ve created a translucent material type for Imagine which allows a more artist-friendly way of specifying the colour and transparency of translucent objects, without having to work out the very unintuitive (until you understand what’s going on internally) absorption and scattering coefficients that control the medium interaction for scattering events and the resulting transmission.
I’m pretty certain it’s not physically-accurate, but it seems to give pretty pleasing results, although I’m still not convinced of the correctness of my implementation, as it’s very easy to produce extremely noisy results.
I got a copy of Volume Rendering for Production for Christmas, so I’m going to be looking into heterogeneous volumes in the future.
I’ve just got Subsurface Scattering working via volumetric rendering with the Henyey Greenstein phase function. This method is completely cache-less (unlike the Dipole method), and I’m currently using single-scattering and attenuated direct illumination through mediums to work out the lighting.
The surface interactions aren’t currently physically-accurate, as I’m just using a diffuse (cosine-weighted hemisphere direction) transmissive BSDF (with no refraction) to allow rays to enter the mesh and the medium, instead of using the BSDF and any IOR of the medium to work out the entry direction through the surface correctly, but the results look pretty good, and most of the infrastructure’s in place now.