Average Global Cloud Cover Satellite Imagery
In a third instalment of attempting to copy images I’ve seen online with my own code, I recently saw some images generated by Johannes Kröger, whereby he ‘integrated’ or averaged a satellite image taken every day from the Suomi VIIRS Satellite into a final image which approximated the median average of cloud cover over the year. He had an original blog post in 2019 here, and a follow-up in 2021 with more technical details here.
I liked the look of the imagery, and was curious how easy it would be to generate myself, and on top of that, was also interested in generating per-quarter/season images rather than ones only for the entire year, in order to try to see obvious variations between seasons.
It should be noted that these will be approximations: the source imagery is taken once a day - generally around noon (although it varies per day per location due to the satellite orbits, as can be seen when comparing adjacent per-day images) - and these processed imagery will include snow/ice cover as well, as shown in this preview of the North Pole area for the approximate average pixel colour of all 366 days of 2020:

Johannes Kröger’s 2021 blog post contained a bash script example which used the gdal_translate command of the Geospatial Data Abstraction Library (GDAL) suite of tools to download the source imagery from NASA’s Global Imagery Browse Services (GIBS) using a web API which provides tiled images, allowing the download of entire images from source tilesets.
I needed to modify his script to get it working (the ‘TileLevel’ needed to be changed), but I didn’t really want to use bash shell anyway, so I wrote a Python script to do the same thing, but added the functionality to also download imagery for multiple days at a time as a date range, and to also use multiple threads to download multiple images in parallel (downloading a single set of tiles for a single date is quite slow), and also added a ‘cubic’ resize filter to the gdal_translate command line args.
The Python script in its final form (albeit slightly sanitised - the save path will need to be changed in order to use it) can be downloaded here.
Note that the size of the images are quite large on disk given their fairly high resolution.
Johannes Kröger did give instructions on how to use available software (GDAL in his case) to perform the ‘averaging’ operation, but this was the bit I wanted to fully implement in code myself: I already had fairly comprehensive Image reading and processing infrastructure code of my own, so modifying it to perform ‘mean’ averages was pretty trivial: to just loop through the entire planar image of each final .tif file for each day’s imagery, and add them all together, and then divide each pixel value by the total number of images. This worked, however the result of using ‘mean’ average pixel values produces an image which does not really represent (at least directly) pixel values that actually occurred in terms of cloud cover: it’s an interpolation, and doesn’t show the pixel values that were most common (i.e. the colour values which occurred the most over the duration of the year for each day).
To find the most common pixel values over the course of the year for each pixel position in the imagery, the ‘median’ average needs to be used, and to calculate this was more development work, as a ‘median’ average requires having all the values for a pixel sorted in order (of luminance/brightness generally), and doing that for 365 16k images at full float32 precision in linear space (despite the source data being in sRGB 8-bit space, it’s generally a good idea to pull pixel values into ‘linear’ colourspaces in order to do computation on them) would take around 1.61 GB of memory (16,384 x 8,192 pixels x 3 channels x 4 bytes) per image, and so it was not going to be feasible to store all 365 entire planar images in memory at once (that would take at least 587 GB of RAM). I could have quantised the pixel values a bit whilst still keeping them in linear space (say to half float16 precision) or something lower with fixed-point, but that still wouldn’t have been anywhere near enough of a reduction, so it was clearly going to require breaking the image up into chunks, so I decided to process the ‘median’ average values in tiled regions, given the source TIFF images were in tiled form anyway, and so reading the individual tile regions for each source image would be easy and pretty fast to iterate through them.
I ended up with an algorithm that would for each tile region (256 x 256 size for the images I had downloaded) of all images (they all obviously have to be the same resolution), iterate through all images for the year, but just for that single tile region at a time, and accumulate all pixel values for all images into arrays per pixel position within the tile region. This way, the total memory usage was “just” the tile size dimensions (256 x 256) x 3 x 4 bytes = 786 KB (plus a bit extra for data structure overhead). Total memory cost for 365 tiles would then be around 287 MB, which is much more reasonable. Then for each pixel position within the tile region, all the pixel values for that pixel position from all the source images needed to be sorted (by luminance), and then the middle ‘median’ value picked. This single RGB value per pixel position within the tile region could then be baked down to a single final image buffer for the tile region, and the memory allocation of all previous pixel values for all 365 tile images could be freed, and then the next tile region could be processed in the same way, for all tile regions in the source images.
Then, finally, these per-tile-region final images would be re-assembled based off their tile position into a final image of the resolution of the original full source images, and this result saved to a final full output image. Given enough memory (my main Linux desktop has 32 GB), it was also trivial enough to process the per-tile-region reading of all source tile images for that tile region and ‘median’ sorting and evaluation in multiple threads, as each tile region could be completely independent from one another, speeding up processing considerably.
Processing 365 16k images into a final output image took around 14 minutes using 12 threads on a Ryzen 5900X, which wasn’t too bad, and there’s still a bit of room for further optimisation I think.
After experimentation with the output, I also added thresholding so as to not accumulate pixel values that were black: the poles of the earth in the satellite imagery were occasionally black, depending on the orbit and that affected the output values a bit.
I had tried to produce average images for the 2022 year, but it turns out the Suomi VIIRS Satellite was missing imagery for late July 2022 and the first half of August 2022, so I used 2021 instead which seemed to have full imagery, and also did 2020 for comparison purposes.
The output result of this for all days in 2021 is this image (full 4k version link):
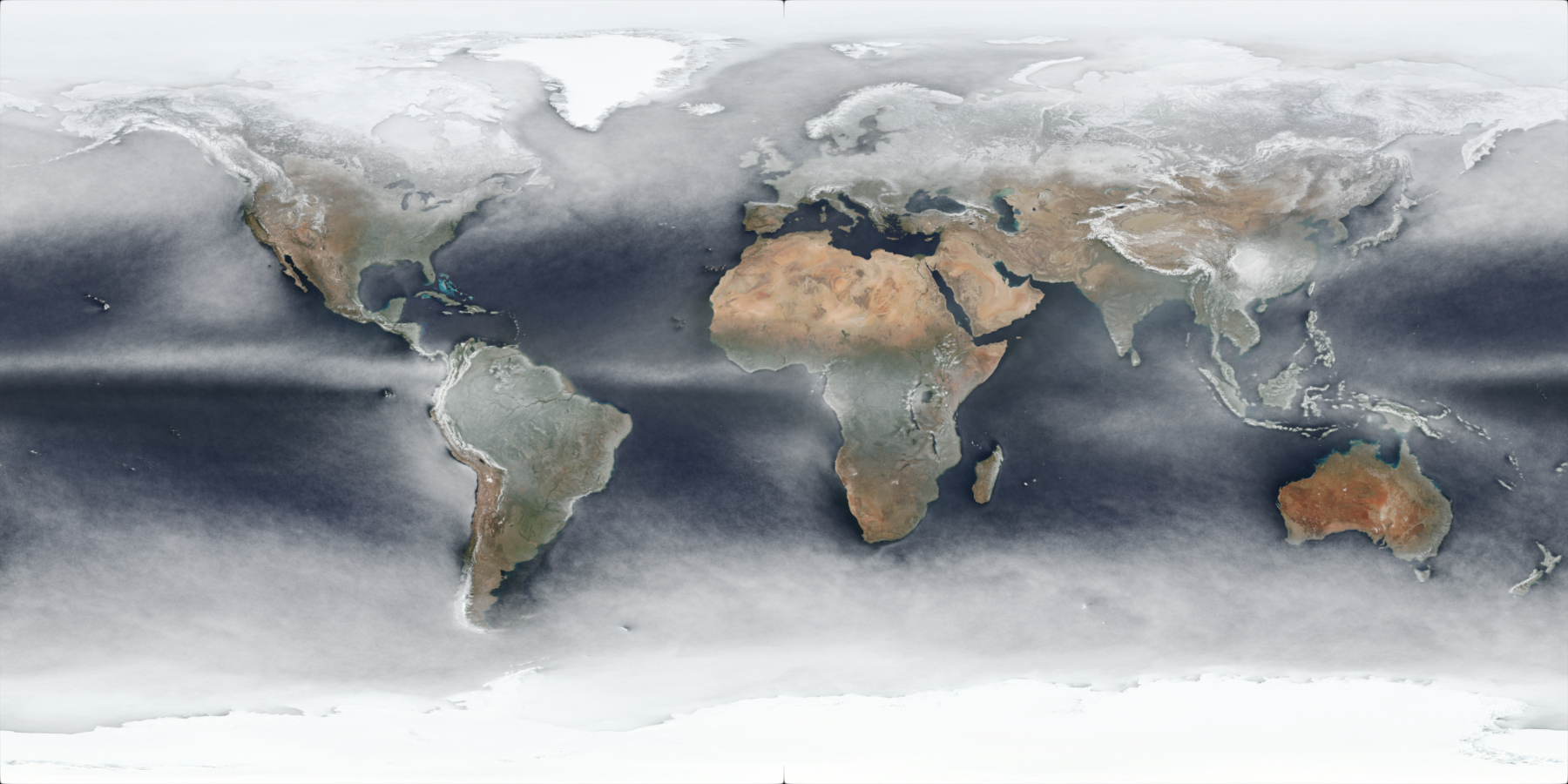
{kind=link}
which is using the same WGS 84 projection that the source images used. Reprojected to a more “true-size preserving” projection - Robinson Projection - provides this image (full 4k version link):

{kind=link}
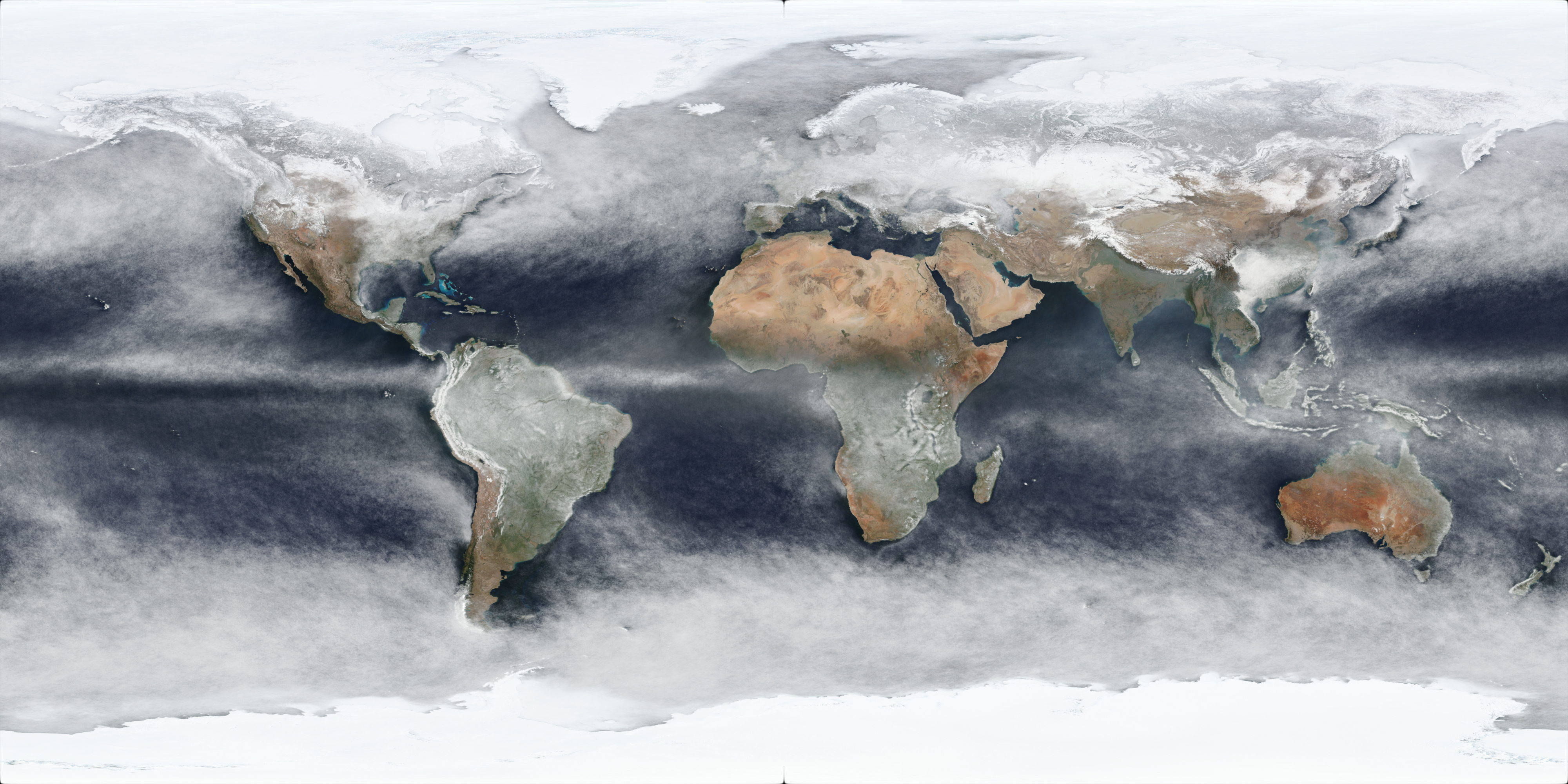
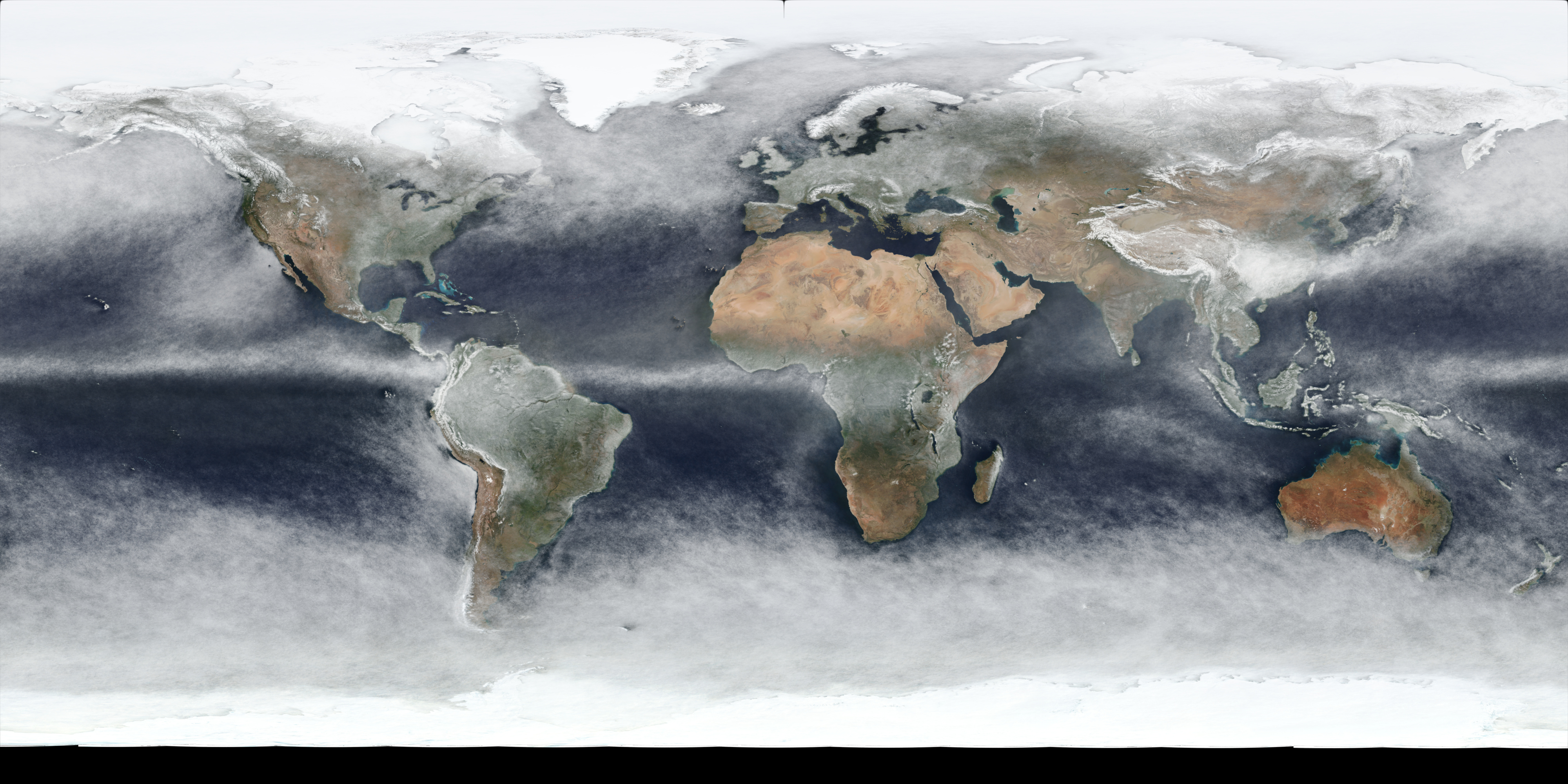
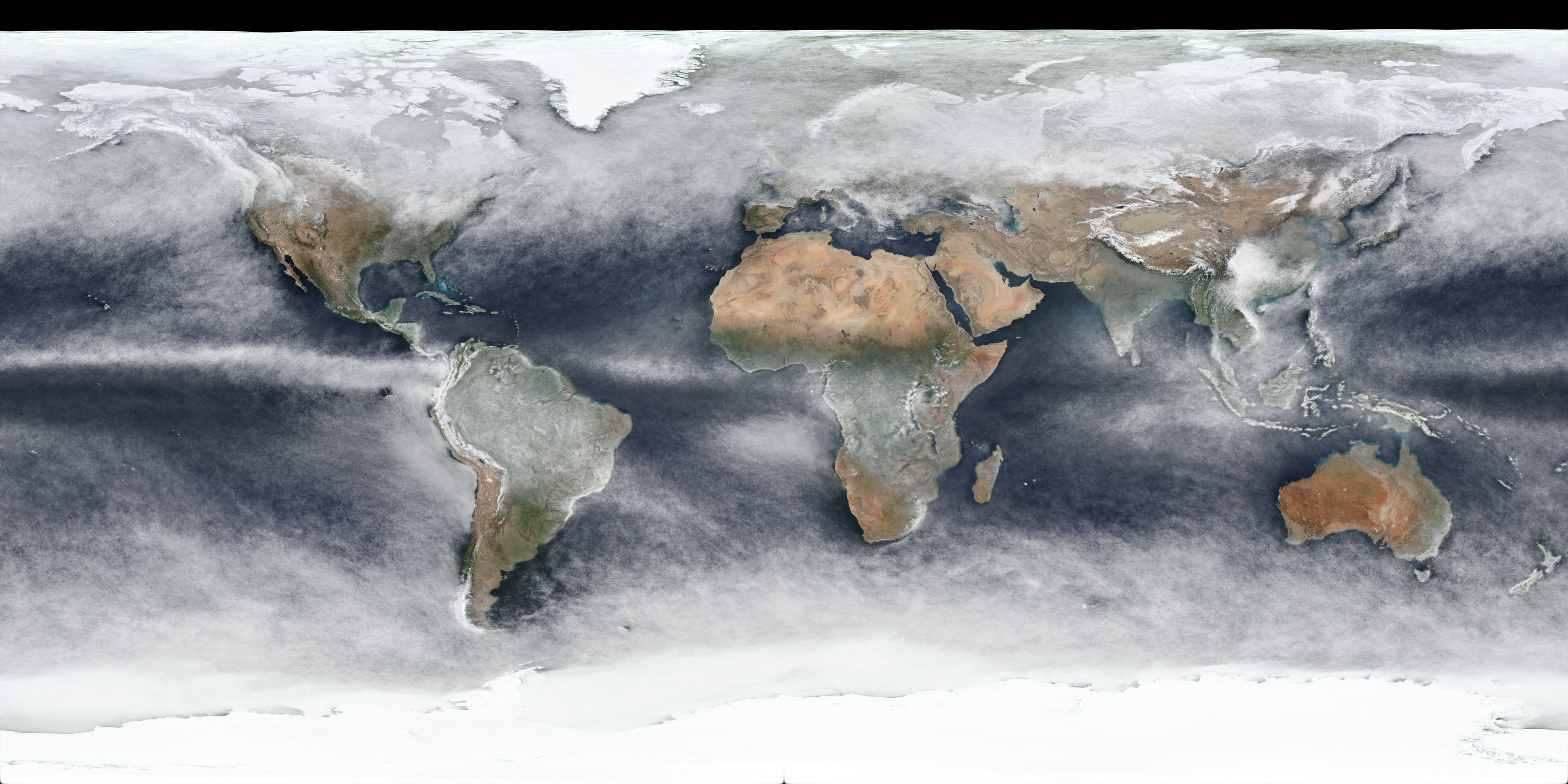
Below is a table containing links to 4k versions of per-quarter images for 2021:
| Description | Link |
|---|---|
| 2021 Q1 (Jan-Mar) | 4k Image Link |
| 2021 Q2 (Apr-Jun) | 4k Image Link |
| 2021 Q3 (Jul-Sep) | 4k Image Link |
| 2021 Q4 (Oct-Dec) | 4k Image Link |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The per-quarter versions do clearly show (as expected) obvious differences in seasons, although there may well be yearly variation as well, and snow/ice cover changes will also be included in the changes.
I’m keen to produce more of these in the future - ideally at higher resolution for more localised regions with better projections - in addition to attempting to generate (mostly) cloudless imagery similar to the famous “Blue Marble” images, to see how easy it is to detect clouds vs snow/ice on the ground: either with large vs. small changes day-to-day between images, or I wonder if it’s possible to use Infrared imagery to detect if colours are likely clouds or not, or by using some of the other output info from the VIIRS sensors.