Last week I returned from a trip to Australia, driving from Sydney up to Sunshine Coast in Queensland, and have just done a first pass of
photo processing. The weather was generally excellent (although it was very windy in Byron Bay and Gold Coast, so walking on the beach was not amazingly pleasant with the sand blowing), and I thoroughly enjoyed the trip and took some photos I’m very pleased with, including several sunrise ones (getting up somewhat early was worth it!).
I’ve just got back from a trip back to the UK for a few weeks, stopping off in Hong Kong on the way out and Singapore on the way back,
which was very enjoyable if also very tiring.
Despite the battery life issue I have with it, the new camera held up well, and I found the Live View functionality very useful for shooting on a tripod and focusing by touching on the screen.
I used this method to tick the box on some (somewhat cliché) location photos in both Hong Kong and Singapore (see below) that I did want to take, and I hope to return to both
places in the future to explore more (although the evidence of political rumblings in Hong Kong was fairly apparent).
Last night I made a more serious attempt at astrophotography of the Milky Way than my previous ones, using my new camera and lens I got a few months ago.
In comparison to my previous astrophotography attempts in years past, I’m pretty happy with the result, but I still need to work out a combination of the best ISO vs noise level to use for single exposures, and whether it’s worth stopping down all the way to f/2.8 or not with the lens.
The Samyang AF 14mm f/2.8 lens I recently bought for this purpose and used I’m not amazingly happy with from a technical/optical perspective - but I did purposefully get it as the cheaper option given the expenditure I’d already spent on new gear back in March, and knew from reviews what its downsides would be ahead of time, so that’s all on me: the vignetting at f/2.8 is very pronounced, and no software currently seems to have the exact profile built-in to correct that, but also it’s sharpest at around f/3.5, and exhibits a fair amount of coma in the corners until f/4.0.
But still, there’s just something about wide-angle photos of the night sky that seems very magical, and even at f/2.8 to my eye at least, it can capture images I’m personally very happy with:
The above photo was taken with a Canon EOS 5D Mk IV, with a Samyang AF 14mm f/2.8 lens, at ISO 2500 with an exposure time of 25 secs at aperture f/2.8.
A year ago I started writing a new basic app (Sniffle) to find log files based off directory/filepath patterns, allowing for recursive directory pattern wildcard matching, and then performing file content operations on the found files, mainly involving grepping/counting items, with an emphasis on finding files on NFS networks. Existing applications like grep, ack and ag (amongst others) do provide existing functionality for some of the use cases, but their defaults are generally wrong for my use-cases (i.e. I want symlinks to always be followed, and to do recursive searching by default), and some of the methods they use to be fast are not always directly compatible (at least efficiently) with NFS networks (i.e. mmap-ing files for better content searching performance).
The number of logs I’d want to search through was often in the tens of thousands, and some of the logs are (unfortunately, and often needlessly) very verbose and can be > 5 MB in some cases. Using a log database or some other similar infrastructure would generally be the more principled way of solving this issue at scale, but I’m generally the only person who occasionally needs to perform these searches, so getting dedicated infrastructure (i.e. a database) for this use-case from IT was very unlikely, essentially meaning I ended up writing my own solution at home in my own time for use at work.
I’ve had working support for finding files, grepping through those files, counting string matches in files and finding multiple cascading strings (optionally in particular orders - i.e. if the first one isn’t found, there’s no point looking for any of the others) for a while now, as well as the ability to filter the list of found files to grep/process first by modified date (e.g. log files last modified within the past 5 days) or file size threshold, but a new use-case came up at work recently where I wanted to look for time period gaps in the log timestamps, indicating that the process writing the logs (a renderer) either hadn’t been doing anything for a while, or had taken longer than expected to do some task.
Checking the time delta between timestamps on consecutive lines in a file is pretty trivial to implement at a conceptual level, however doing so in a way which is performant is a bit more work: naively using strptime() to parse the time has a significant and noticeable overhead, due to internal use of mktime() which is very expensive, and even using sscanf() to pull out the constituent parts and rebuild them, or using a series of atoi() calls - while noticeably faster than strptime() - can be improved upon if you’re just extracting digit components in known positions (although supporting multiple date-formats complicates this slightly).
Given a fixed and valid timestamp string with consistent width zero-padding - which I could validate and guarantee in my use-case - I ended up settling on subtracting each string character value per timestamp unit digit by the char value '0', to give the 0-based 0-9 integer value, and then multiplying it by its digit position in the component number and adding these values together grouped by component number, effectively extracting and accumulating final values very quickly.
It’s somewhat hacky and verbose, but demonstrably faster than the more normal approaches mentioned above, which for my purposes made it a worthwhile optimisation.
As an example, given a std::string currentString; representing a non-empty log line which is guaranteed to have at least the minimum number of string characters for an ISO 8601 date/time stamp, and size_t timestampStart representing the character position offset within the string where the timestamp starts (in order to support varying formatting around the timestamp), with the start of a log line looking something like this:
[2019-03-22 09:42:13] Did something useful
then code to parse the year from the string looks like this:
and handling the time components is done similarly with appropriate position indices.
Using these component integer values to represent a full time value is now context-dependent on what’s trying to be achieved: if you just wanted to sort the timestamps, you could just accumulate the numbers, multiplying each component by a component-respective multiplier to build the number of seconds, i.e.:
In other words, using a constant of 31 for the number of days in all months: because we’d only care about relative positions based on numbers for sorting, and not absolute deltas, it wouldn’t be necessary to use the correct number of days in the month.
However, for the use-case of working out time durations between each log timestamp, absolute delta values are required, and this does involve knowing the number of days within each month - so that you accurately know the difference between 23:55 on the last day of a month is 10 minutes before 00:05 on the first day of the month, which makes things a bit more complicated. I ended up using two pre-calculated static const arrays of the months,
one for non-leap year years, the other for leap year years, i.e.:
// pre-calculated totals for numbers of days from start of year for each month
static const unsigned int kCumulativeDaysInYearForMonth[12] = { 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334 };
static const unsigned int kCumulativeDaysInYearForMonthLeapYear[12] = { 0, 31, 60, 91, 121, 152, 182, 213, 244, 274, 305, 335 };
and then working out whether the year was a leap year by cheating a bit and only checking the first timestamp on the first line of the logfile to see if it was a leap year, and then caching that in a variable for the rest of the log processing:
which then meant not needing to do any branching for any of the remainder log line timestamps to work this out, and being able to build up the number of seconds
a timestamp represented with:
which then works to provide exact absolute counts of the number of seconds the timestamp represents for nearly all situations, except for two:
The first line of the log file having a timestamp almost two months before the end of February, e.g. December 30th, and some following log line timestamps in the same log file then progressing on to the end of February, potentially meaning there was a discrepancy between the code thinking the year was a leap year or not
Daylight Savings Time changes
Both of these situations in the end I decided to ignore: the first one because it was a total non-issue for my use-case, as if the length of the log files timestamps stretched to almost two months, straddling a new year and then on to the end of February, there would be much bigger issues to worry about: almost all log files should have had a duration of under 48 hours, and anything over two weeks long would be a pathological situation.
For the Daylight Savings Time change, while it was a definite potential issue that could happen - either adding an extra hour or removing it from the time value in the hour after the change - which could then have tripped or not tripped the time delta threshold logic incorrectly, I was happy to let that problem slide: dealing with DST changes in computer systems is almost always problematic in my experience (especially if using local timestamps like here), and while it was technically solvable if you know the dates it changes (per geographic location: different countries change at differing times during the year, and the Earth hemisphere matters as well for direction), I just didn’t feel it was worth it for the potential of some false positives/negatives happening within two to three hours per year.
A few weeks ago I splashed out a rather alarming amount of money on a new DSLR camera (Canon EOS 5D Mk IV) and a new lens (Canon EF 24-70mm f/2.8L II USM), both upgrades from the previous versions of each. I certainly didn’t need new versions of either, and to some extent it was one of my fairly silly impulse purchases that I end up regretting after clicking the ‘Purchase’ button, but I’m travelling back to Europe for a few weeks in two months, and I wanted a camera with GPS built-in for geo-tagging photos, more megapixels (stitching panoramas of water doesn’t work perfectly), a use-able live-view, in addition to having better low-light performance. It will also likely guilt me into getting back into photography a bit more, which this blog post is also an attempt to do. I did semi-seriously think about jumping to mirrorless with Sony, but I do like Canon gear (they are behind technically currently though) and I have several Canon lenses, so it wasn’t an obvious win for me to make the switch.
I’m relatively happy with the new camera and lens: the new II version of the lens is noticeably shaper, although the vignetting falloff/gradient is also much more pronounced than with the old version, and the distortion’s different - although both of those can be corrected in software. The GPS geo-tagging is useful, but unfortunately I’ve found the battery life of my camera is really bad, as even with GPS totally off (there are two “Enabled” modes as well as fully “Disabled”), within a day of the camera being turned physically “Off” with the battery fully-charged in my camera bag and GPS mode set to “Disabled”, the battery’s consistently drained, and this is happening with multiple Canon batteries (including the one the camera came with), so I’m really not happy about that aspect. I think something must be wrong with my copy electronically, as a colleague has a Mark IV as well without the issue, and clearly most people online don’t seem to have the issue. At some point I’ll send it in to Canon to get it looked at and hopefully fixed, but pulling the battery out of the camera works around the long-term storage problem for the moment, and on trips abroad I’ll likely be charging batteries every night, so it’s not the end of the world.
The exposure sensitivity of the Mark IV also seems quite different to the Mark III: I’m having to stop down one or two stops to match the Mark III’s levels - I guess the light metering is more accurate or something (although I’d argue photos are getting overexposed with it compared to my Mark III with neutral exposure), but that’s not really a problem if I just keep the setting stopped down on the camera to match the results I got with the Mark III (which seem more controlled and less over-exposed).
In a further act of semi-madness, I also ordered a Samyang AF 14mm f/2.8 lens which from reviews looked like it was one of the cheapest wide-angle primes for astrophotography that still had semi-reasonable performance, as I’m very keen to try and get into astrophotography after several previous failed attempts. I’ll be giving that a go when it arrives, and when the night sky clears up and the wind dies down (need a heavier tripod!).
This is another comparison of C++ compiler benchmarks on Linux using my Imagine renderer as the benchmark, almost three years since I did the last set of benchmarks.
This time, I’m only comparing versions of GCC and Clang, but I am also comparing the -Os optimisation level in addition to -O2 and -O3.
As with the previous benchmarks I did, I’m sticking with just comparing the standard “stock” optimisation levels, as it’s generally the starting point for compiler flags, and it makes things a fair bit easier, rather than trying every single combination of flags different compilers can support.
As it stands now, Imagine consists of 143,682 lines of C++ in 458 implementation files (.cpp), and 68,937 lines of C++ in 579 header files, for a total of 212,619 lines of code.
The compilers that I’m comparing are:
GCC 4.8.5
GCC 4.9.3
GCC 5.4
GCC 6.3
GCC 7.1
Clang 3.8
Clang 3.9
Clang 4.0
Clang 5.0
GCC 4.8.5, GCC 5.4 and Clang 3.8 were Ubuntu packages, the other versions I compiled from source, using the methods recommended in the respective documentation.
The machine the tests were run on is the same machine the previous benchmarks were run on, but it now has an SSD system disk (which I ran the tests on in terms of target compilation), and a more up-to-date Linux distribution (Ubuntu 16.04 LTS). The machine is a dual socket Intel Xeon E5-2643 (3.3 Ghz) of Sandy Bridge vintage. Imagine’s code has also changed quite a bit in key areas, so these tests can’t be directly compared to the previous tests.
This time I didn’t run any microbenchmarks, just three different renders of different things in Imagine, basically rendering three different scenes. Due to the amount of things Imagine will be doing (ray tracing, light transport, material evaluation, splatting, etc, etc) this does mean that there’s a fair chance that code generated for different aspects can’t really be identified, as the timing will be for the render as a whole, but I think it still provides some indication as to what the compilers are doing relative to each other.
First of all I compared compilation time of all the compilers, building all of Imagine using different numbers of jobs (threads), from 16 (the total number of logical cores / threads my machine supports), down to 2. This was to try and isolate how parallel compilation can be (in particular with hyperthreading) when disk IO is a factor. Imagine’s source code was on an SSD, as was the directory for compiling.
Three runs from clean were done with each combination, and the time was timed with the command line ‘time’ command in front of the ‘make -jx’ command.
The graph below shows the results (mean averages).
As can be seen, there’s a fairly obvious pattern of O3 builds taking slightly longer than O2 builds, and Os builds taking slightly less than O2 builds as one would expect. In GCC, going from 8 to 16 threads (so effectively using hyperthreading on the machine, although it’s not clear what the scheduler was doing) gave practically no benefit in the older GCC versions, with a possible tiny benefit with 6.3 and 7.1, although 6.3 and 7.1 take noticeably longer to compile than older versions.
Thread scalability after that is relatively close to linear, the difference probably being link time which cannot be parallelised as much.
Clang is consistently slower than GCC to build. I saw this in my previous tests I ran almost three years ago, and while in those tests I incorrectly enabled asserts when building it from source, making Clang builds slightly slower, even when disabling asserts back then it was still slower than GCC. This time I made sure asserts weren’t enabled, and it still seems to be slower than GCC, which seems to be against conventional wisdom, however it seems pretty consistent here. 5/6 years ago, I definitely found Clang faster to compile than GCC (4.2/4.4) when I benchmarked it, but that no longer seems to be the case.
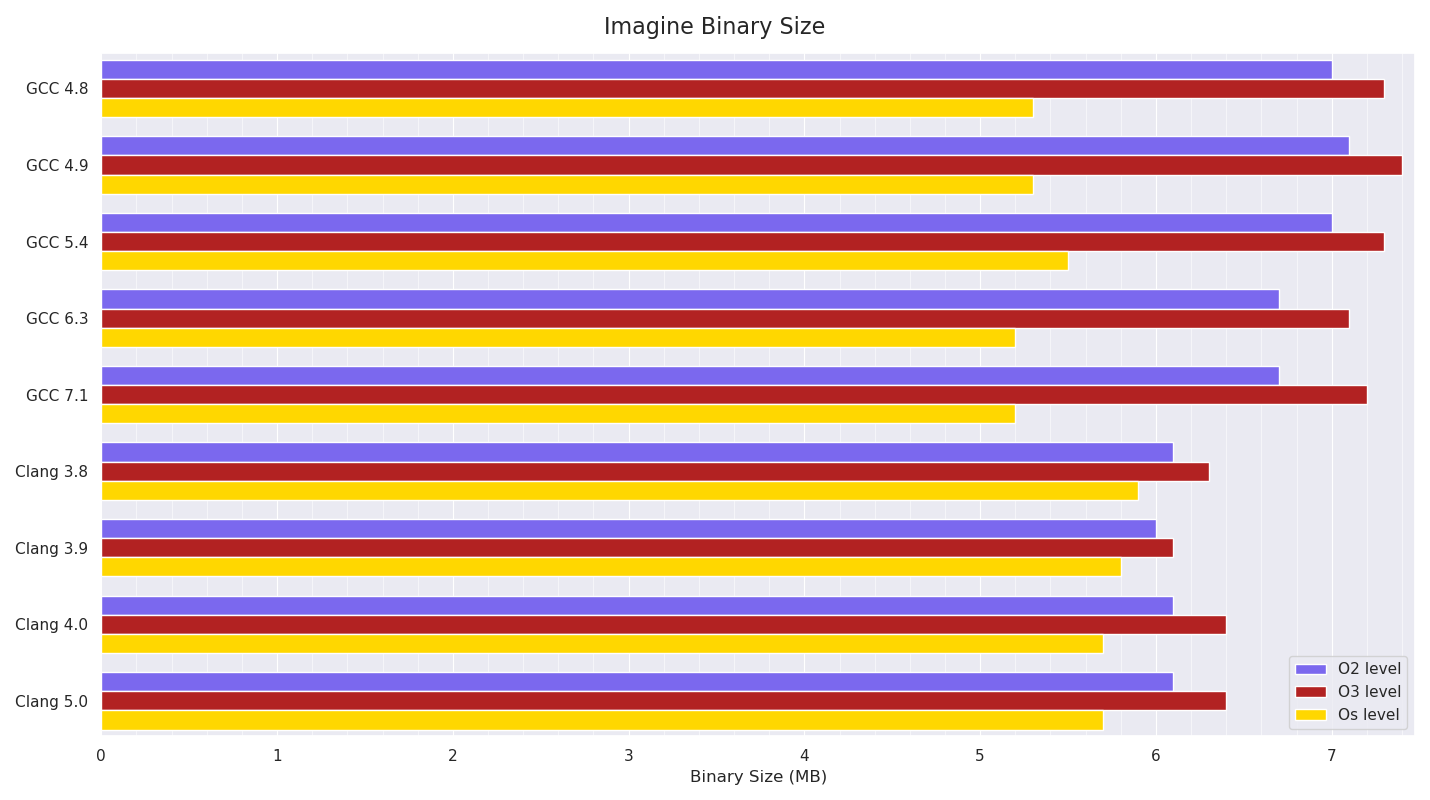
Executable Size:
Below is a graph of the resultant executable size:
The pattern of O3 builds being bigger than O2 builds due to more aggressive optimisations (probably mainly more inlining and loop unrolling) is visible, and it’s noticeable how much smaller than O2 builds GCC’s Os builds are compared to Clang’s.
Rendering benchmarks
Scene 1:
Scene 1 consisted of a Cornell box (floor diffuse procedural texture with Beckmann microfacet spec lobe, walls diffuse + Beckmann microfacet spec lobes), with one bust model consisting of 544k triangles with a conductor microfacet BSDF (GGX), a dragon model consisting of 535k triangles with dielectric refractive lobe with brute force internal scattering for SSS with multiple scattering, and Beckmann microfacet dielectric lobe.
Three area lights (two quads, one sphere) were in the scene, each of which was sampled per hit / scatter (for next event estimation).
The resolution was 1024x768, with max path length of 6, using a volumetric integrator (which calculates full transmission for shadows, so it can’t early out in most cases), in non-progressive mode, using 144 stratified samples per pixel in basic pathtracing mode (no splitting) with MIS. The Mitchell-Netravali pixel filter was used for splatting.
Scene 2:
Scene 2 again consisted of a Cornell box, but with more basic materials (only the back wall had a spec lobe on in addition to diffuse), with two quad area lights, and a dense voxel grid volumetric bunny (converted from OpenVDB examples) with an Isotropic phase function. The resolution was again 1024x768, with max path length of 6, with 81 stratified samples used in non-progressive mode.
The volumetric integrator was used, with Woodcock tracking volume sampling for the heterogenous voxel volume, with multiple scattering, and two transmittance samples per volume scatter event per light sample. Both lights were sampled per surface and volume scatter event for next event estimation. Volume roughening (falling back to nearest neighbour voxel lookup after ray roughness / throughput reaches a threshold) was turned off, so full trilinear voxel lookups were always done.
Scene 3:
Scene 3 consisted of a single 10M triangle mesh of a scanned church ornament, with a diffuse texture provided by a 1M point pointcloud lookup texture (KDTree).
A very large filter radius was needed on the point lookups, due to the weird arrangements of the colour point values in the pointcloud in order to not have gaps in the resulting texture. A constant Beckmann spec lobe was also on the material.
A single Physical Sky Environment light was in the scene, with Environment Directional culling (culling directions on the Environment light that aren’t actually visible from the surface normal) disabled.
The resolution was 1024x768, max path length was 5, and a non-volumetric integrator was used this time, meaning occlusion ray traversal could early-out instead of having to find the closest hit and test transmittance through materials as the volume tests above had to. 81 stratified samples per pixel were used in non-progressive mode, with MIS path tracing.
Performance Results
Six runs of each were done, restarting each time to account for possible different memory layouts - Imagine is NUMA aware where possible, trying very hard to allocate and write (first touch) memory dedicated to the core/socket that will be running, but some things like triangles / geometry / acceleration structures can’t really be made NUMA-aware without duplicating memory which doesn’t really make sense, so it’s somewhat down to luck where memory will be (in terms of attached to which socket). 16 threads were used for rendering, and render thread affinity was set. The times are in seconds, and are for pure rendering (no loading, scene building or acceleration structure building included in the times), and were measured with code within Imagine.
Mean averages are graphed below.
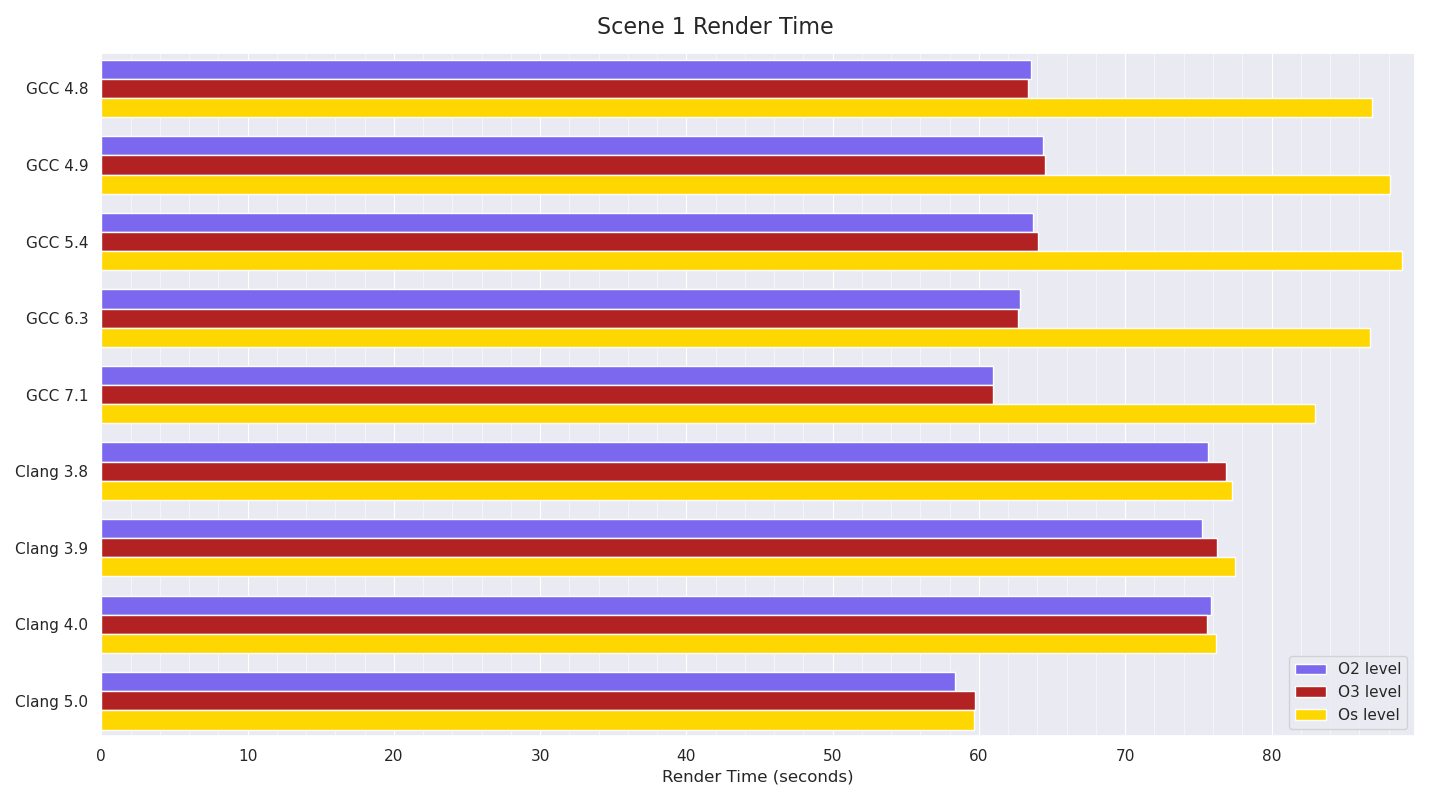
Scene 1
Scene 1 results show GCC 7.1 made some improvements over previous GCC versions, and that GCC’s Os builds are noticeably slower than its O2 or O3 ones. Until Clang 5.0, Clang was noticeably slower than GCC, however Clang 5.0 managed to just beat GCC 7.1’s numbers. Interestingly, Clang’s Os numbers show almost no difference to its more optimised builds, in contrast to GCC’s ratio between the optimisation levels.
Scene 2
Scene 2 shows a regression in performance going from GCC 4.9 to 5.4, which still hasn’t been recovered in GCC 7.1. Clang wins these by a comfortable margin.
Again, Clang’s consistency between different optimisation levels is very close, in contrast to GCC’s, which is more pronounced.
Scene 3
Scene 3 is fairly similar to Scene 1 in that GCC 7.1 makes slight gains over previous GCC versions (and is the fastest), while until Clang 5.0, Clang was noticeably slower than GCC. Clang 5.0 almost makes up the gap to GCC 7.1.
Conclusion
Given these benchmarks are pretty much “overall” benchmarks, given within each test Imagine is doing so many different things, it’s very likely things are averaging out between the compilers,
however, it does seem that Clang 5.0 made significant improvements over Clang 4.0 in two of the tests, becoming the new fastest in Scene 1 and almost matching GCC 7.1 in Scene 3. GCC 7.1 is the fastest in Scene 3, and almost the fastest in Scene 1, but GCC’s speed regression from 4.9 -> 5.4 in Scene 2 still impacts GCC 7.1, meaning Clang completely dominated Scene 2.
What was very interesting to me was the speed penalty GCC’s Os builds have compared to Clang’s Os builds. Given the executable size graph shows a similar ratio in terms of GCC’s Os builds being noticeably smaller than GCC’s O2 builds than Clang’s Os builds are than Clang’s O2 builds, it seems fairly obvious from the executable sizes produced that Clang is still fairly aggressively optimising Os builds, in contrast to GCC which seems to much more strongly prioritise smaller executable size.
Over the past year I’ve been working on (and to a much greater extent optimising) an image texture cache system for Imagine.
Imagine has had some form of reading planar (entire) images since very early on, but other than a slightly hacky integration of OpenImageIO (but that did work efficiently) into Imagine just to test things, it hasn’t had proper integrated support for reading (and more importantly paging) partial images lazily on-demand. This ability is essential for a production level renderer in VFX, as the size and number of image textures used in VFX for rendering is pretty extreme.
I could have just integrated OpenImageIO properly into Imagine, but there were a few reasons I didn’t want to do this: First and foremost, I wanted to write my own and experiment with different ways of handling concurrency, scalability as well as eviction. Second, I already had my own file readers / writers and didn’t like some of OIIO’s dependencies. Further reasons were that OIIO comes with a fair bit of baggage which at least in my use-case for texture reading, I didn’t care that much about: in particular rather bloated data structures in some cases (partly due to Field3D support requiring matrices). It also had some limitations: didn’t support constant tiles, although in fairness there aren’t any open file formats that support this, although I’d like to investigate creating a file format at some point - which can make a huge difference in terms of File I/O bandwidth (which is a very important bottleneck for high-end VFX rendering), it doesn’t natively support texture atlassing (e.g. UDIMs) and I was also not completely convinced by its efficiency or scalability, although it definitely is a capable and production-proven library. I also wanted to experiment with adding new features like on-the-fly compression of tile data, and doing this in a clean and minimal code-base would be much easier.
Imagine already had file readers, but they only supported reading planar images into image buffer classes, so the first step was to provide the ability for a file reader to describe the metadata of an image file, and fill in the details, including resolution, number of channels, data type and mipmap levels.
In terms of general storage of image textures, I created something that’s essentially similar to OpenImageIO’s overall design, whereby there are two main items stored in the cache: image items, which represent the actual image file metadata, and image tiles, which represent the pixel data of the images themselves, broken into small tiles. However I wanted to try slightly different algorithms to what OpenImageIO uses for tile eviction, as I had the suspicion the method it uses (mark and sweep iterator over entire tile cache) wasn’t the best approach from a speed and scalability perspective. One of the ideas I had in mind was not actually removing any tile items at all at eviction time, but only freeing the pixel data itself. This would use more overall infrastructure memory (excluding pixel data), but it should reduce the need to lock the entire tile cache very slightly, which hopefully would help scalability and performance. Given that classes and structs representing texture items and texture tiles would never be freed at tile eviction for paging, it was therefore extremely important that they be as memory efficient as possible.
I made a conscious decision to not separate different channel images based on tiles requested based on the channels requested - that is, if an RGBA image was loaded, but only the A channel was requested, I’d still load all four channels into memory instead of partitioning each tile and having an extra dimension to have to cope with for the tile hashes. This was partly to keep things simpler, but also to constrain the number of tiles given I wanted to not have to free the tile items at all when paging, only freeing the pixel data. It would mean however, that in certain situations like the example given above, memory usage would be higher than needed. However, as is generally done in high-end VFX, the solution here is to make sure each texture image just contains one set of channels, so the above example would have two textures, one for the RGB channels and a separate one for the A channel.
I also made a decision to not use lazy texture loading for HDRI environment maps, but to keep those separate, partly because you’re effectively point-sampling them anyway (definitely at construction time to build the CDFs), but also to keep texture requests down for this type of illumination.
I also wanted to be able to categorise images based on purpose, both for allowing different caching / eviction strategies for different types and to allow different types of filtering to be done on them: there are some situations like for alpha/presence maps and layering mask/mix maps that it’s generally better to err on the side of less filtering, even at the expense of possible aliasing.
To begin with I started with just the bare basics as I wanted to investigate and experiment with different ways of doing things to see the effects they would have. As a starting point I initially just had a single mutex around each map collection, so that I could see what the extreme worst-case scenario was.
Imagine was using ray differentials to calculate texture filter regions and thus the mipmap levels to pull in of the textures, and doing trilinear filtering to combine mipmap levels.
Tests even with just a single plane polygon in the scene with one texture were as expected pretty abysmal, with CPU utilisation on a 16 core / 2 socket system hovering around 300% (instead of the ideal of 1600%).
I implemented per-thread microcaches that stored LRU arrays of pairs of both the texture items and their hashes and tile items and their hashes, which was used to lookup textures before going to the main cache and in this contrived scenario, other than for the first few buckets where all threads were initially opening file and reading images, CPU utilisation went up to the expected 1600%, fully utilising the available cores.
Testing with other simple objects added to the scene with the same texture (so that there were now indirect rays being fired in an incoherent fashion) could scale to a degree if I increased the microcache sizes, but this wasn’t going to be a good approach, as the single mutexes around the individual map containers were clearly the bottleneck.
So I needed to come up with a solution which would scale well with many threads. In the end I settled on writing my own map container wrapper similar to Java’s ConcurrentHashMap (which is also similar to what OIIO uses, and how Linux’s hashed spinlocks work), which splits the map into different “bins” (although I called my version “shards” which is more in mapping to the database partitioning technique). Each “shard” contains its own isolated map and mutex, and the shard to use for lookup and inserting values is chosen by using the modulus of the hash value for the key, based on the number of shards. It’s then possible to lock just this shard and lookup within its individual map to find / set the value as required, while other concurrent requests from other threads will have no contention, so long as they map to different shards. If they do map to the same shard, then there will be a certain amount of contention. So it’s extremely important to have a very good hash function which distributes well over the domain space. In my case, after an awful lot of trial and error and playing around with the avalanche effect of hashes for tiles, I came up with hashes which seem to work quite well: I used Austin Appleby’s MurmurHash3 for hashing the filename, generating a 32-bit integer, which allows lookups of the texture item itself.
For tile items, I ended up using a 64-bit integer of the 32-bit texture item hash shifted 32-bits to the left, being added to by the mipmap level shifted 24-bits to the left, then the tileY coordinate shifted 14-bits to the left with the final tileX coordinate unshifted.
Another very important factor which was important is mixing the hash used to lookup the shard so that it doesn’t have the same correlation within the shard’s hash map, which can severely affect the efficiency and load factor of hash maps within each shard.
With this implementation, scaleability was perfect on 16 threads with these simple scenes, so I then attempted to stress-test it with more complex test scenes and finally as close to a production level scene as I could fabricate texture-wise.
I tested initial scalability of the locking by using “virtual” image texture readers which just generated texture colours procedurally (tiled based) so as not to be limited by disk speed or OS-level disk caching.
Tests with the extreme worse case scenario (just a single mutex around the containers - and using the less-than-ideal std::map<> to begin with for lookup structures) were understandably atrociously bad, although interestingly scaling on Linux was much better than on OS X, probably due to Linux’s Futexes.
Scalability with sharded maps was much better on OS X, and noticeably better on Linux, scaling close to linearly with 32 shards for both maps. Changing the underlying map type to std::unordered_map (hashmap) reduced lookup time by around 25%, which was not as much as I had hoped. I experimented with setting the initial bucket count and max load factor for the maps and this reduced lookup time by around 10% again, and at this point I was slightly worried that my hashes weren’t as well distributed as I thought - so I thought this would be a good time to both check the distribution of the hashmaps and see if the strategy of not deleting items from the maps gave any benefit. Without controlling the load factor and initial bucket count, once paging started happening, not deleting items seemed to give a slight speedup - possibly due to the fact tombstones didn’t need to be used to mark items as deleted. However when optimising the initial load factor and bucket count, the difference was negligible - probably due to hashes mapping very nicely to open buckets with very few collisions happening. However the ability to not delete tile items did mean that in the texture stats I was able to very accurately track unique texture data read during paging, which is quite useful, and I kept this as an option.
I experimented at this point with increasing the microcache sizes a bit (to 16 entries per thread for both), and for simple scenes with less than 60 textures this made a noticeable difference (especially with paging enabled, as it meant if an item was in a microcache it was recently used so it shouldn’t be evicted), but once each ray hit was evaluating more than 10 textures for layered materials, these microcaches became barely useful due to almost random thrashing between vertices per path. I have some ideas for trying to use more tree-like data structures for them in order to take advantage of ray-tree coherence, but the best approach here would just be full-on deferred ray batching / sorting, so I’m not convinced it’s going to be worth it.
At this point without having to page textures to fit in a particular memory limit, my texture cache was faster than OpenImageIO for pretty much identical numbers of texture evaluations, but with aggressive paging turned on OpenImageIO was noticeably faster. Looking at the stats between the two, it was obvious that my naive eviction method was causing an awful lot of duplicate reads (still using virtual file readers, so no disk access was taking place, only memory allocations and procedural textures). I decided to just copy OpenImageIO’s clever method of marking a tile as recently used with an atomic variable, allowing a very cheap compare-and-swap to be done, allowing skipping recently-used tiles very accurately and efficiently, although with a slightly less cumbersome mark-and-sweep process. This change made a huge amount of difference, with my texture cache now being ~5-10% faster than OpenImageIO. I also experimented with over-evicting based on a ratio to prevent continual locking: if a request for a new image needed 2KB of data, I’d actually free more than that, so as to do more work within the one lock event meaning it would be more likely the next request for a new texture would not need to lock as well to evict - this made a noticeable improvement (after experimentation I settled on doubling the target eviction size).
I then decided to move to proper tiled based image textures, testing both TIFF (briefly) and OpenEXR. I noticed immediately with OpenEXR that using the worker thread calling OpenEXR to read images (i.e. with the threadpool size set to 0) had severe contention issues, caused by redundant locking in IlmBase’s ThreadPool class. Larry Gritz had also spotted this issue previously and had a fix for it on GitHub which allowed EXR reading with worker threads to scale a lot better. Along the way of testing with bigger and bigger scenes I had to fix several issues with ray differentials not propagating correctly causing incorrect point-sampling of the lowest level mipmaps, which obviously slows things down to a halt. In the end for some edge cases I had to build in texture filtering based on approximate ray-width as a backup for when ray differentials failed (due to incorrect/inconsistent UVs or missing UVs on meshes).
I then decided to scale things up to an extreme test to stress test the cache: I tested with a large cornell-box style scene containing four production-scale hero objects - many different components with different materials, all with UDIMed textures with varying numbers of layers (one to three, controlled with mask textures controlling mixes), with diffuse, specular colour, specular roughness, clearcoat reflection and bump textures being utilised for most (but not all) materials. The floor and the walls of the Cornell box also had diffuse textures of 10x10 tiles of UDIMs (so each plane other than the ceiling consisted of 100 texture files).
The total number of image texture files was 898, and I made use of OpenEXR format tiled mipmaps of 16-bit half format at 8K, the tile size being 32x32. Total size on disk for all textures was over 320 GB.
I tested with path length set to 6, so there would be a large amount of incoherent texture accesses.
Testing this scene showed it worked very well, and was consistently slightly faster than OIIO - this is probably partly due to less locking that I do in general, but probably also because my texture cache has full integrated support for UDIMs, so can batch up requests to adjacent tiles on UDIM borders and when filtering to reduce locking even more.
I experimented with adding support for compressing pixel tile data in memory using LZ4 - the idea being that for constant tiles (which no open standard tiled file format supports at present, so there’s no way to detect them up front) it might be a way to detect these on-the-fly with a tiny bit of overhead. Testing with simple textures worked well, and if the compression ratio was excellent it was obvious it was a constant tile, and I could mark it as such and not bother evicting it, which brought a slight speed-up. If the compression ratio was just good, there was some constant data in the tile, and it meant I could fit more in memory without going back to disk when paging. However, with real-world textures painted in Mari it didn’t work as well, as outside the UV’d area Mari tends to distort texture detail instead of leaving it black, so there’s still texture detail there taking up space. One situation where compressing did still provide benefits with real-world textures was with layer masks texture maps used for mixing / isolation, which are generally less detailed anyway - it was possible to often detect constant tiles and even if there weren’t entire constant tiles still compress image data usefully within tiles.
So I now have a very fast, efficient and scalable image texture cache - I still think there could be better texture formats than OpenEXR which unfortunately has become the standard for textures at VFX level but is seemingly somewhat abandoned: OpenEXR’s threading is really bad, and the use of threadpools doesn’t really make sense for reading multiple random tiles per random mipmap level in parallel in a path tracer - it’s possible with coherent access using threadpools is still a win for rendering (it definitely does make sense to use threadpools to speed up reading a single large entire image for use in image viewers and compositors, and for writing images), but I think it makes sense that a file format for rendering be completely stateless, with metadata decoded once, and then any number of threads be able to read/uncompress at will without dependencies / state controls - obviously depending on how the image is compressed there may be problems here, but a balance needs to be found. In addition OpenEXR doesn’t support 8-bit or 16-bit integer formats which can be very efficient for certain types of data (masks / isolation maps), neither does it support constant tiles or instanced tiles. So I’m tempted to try creating a texture format just for rendering, optimised for extremely fast random access.