Over the past few years, as well as learning the Rust programming language, I’ve also been attempting to learn more about the JavaScript ecosystem for front-end web development as well, although the seemingly large number of different libraries/frameworks available has made that a somewhat daunting task in terms of starting point. Because of this, I had decided not to just learn generic and popular web frameworks that were the most popular ones at the time of learning, but to explicitly use ones that seemed to match well with particular use-cases I had in mind.
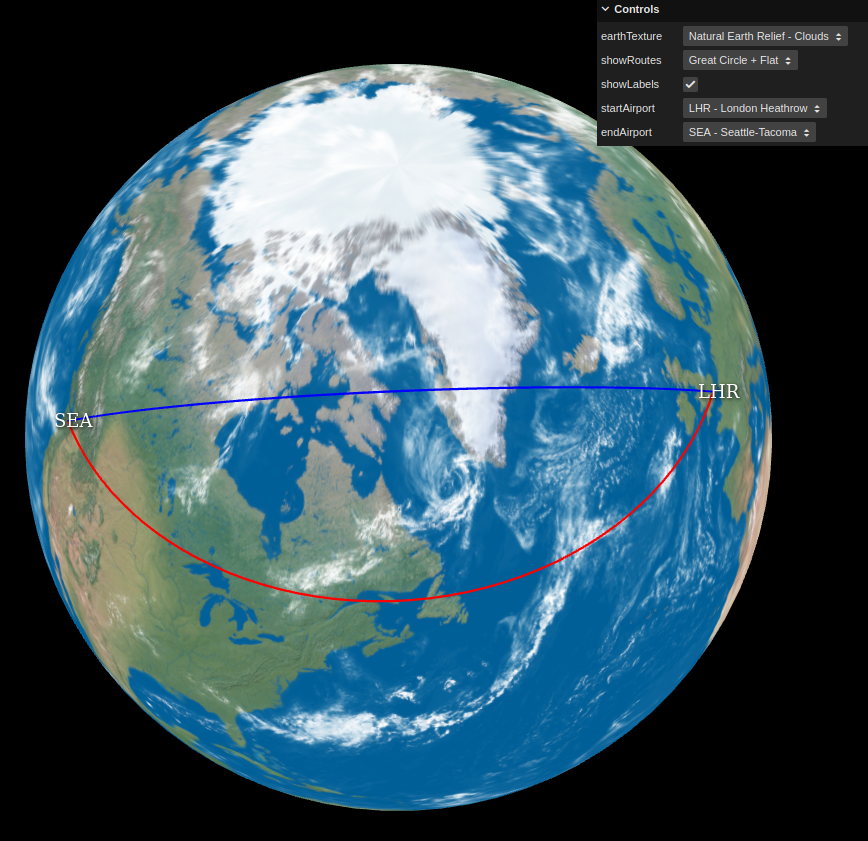
In this case, I’ve been writing a basic web app for visualising Great-Circle Routes (link to app here) between common airports. There are various existing ones on the web in some form or another, but many produce only flat 2D visualisations, and while there are one or two 3D ones showing the routes on a 3D globe, they weren’t exactly to my liking, and regardless, it provided me with an interesting use-case with which to gain some more experience with JavaScript and web-based real-time rendering.
I did at first think about sticking to core vanilla JavaScript and using WebGL directly with no use of additional frameworks/libraries, but given I wanted something working fairly quickly, I decided that using a library would be the more efficient solution, and a quick look at https://threejs.org/ and its capabilities re-enforced that decision.
In the end, it was pretty simple to come up with a basic working example, with a sphere mesh object with a diffuse earth texture on, with an orbit-able camera, with “route” line meshes representing the Great-Circle Route and “flat” 2D route in question being drawn based off spherical coordinates in 3D space from source latitude and longitude coordinates. The Great-Circle Route between two points was calculated by using the Haversine Formula.
The most “complicated” thing in the implementation ended up being the Airport text labels: while it was simple enough to use THREE.CSS2DObject to construct high-quality DOM text items that appear in the correct 2D screen position based off the camera/earth position of where the respective airports are on the sphere, occlusion/visibility handling isn’t done automatically with this setup, as the DOM elements are not actually part of the 3D scene, they’re layered on top. So in order to hide the label text of airports when they’re occluded by the Earth sphere geo (i.e. when they’re around the back of the Earth to the camera), I ended up having to send Raycaster queries to detect the visibility of the position of the airports from the camera, and adjust the visibility of the Airport label CSS2DObject objects based off the result of these queries within the main render loop. This was still quite easy to do however, and seems to work well enough, although doing the raycaster queries within the render loop is probably not the most optimal solution in terms of efficiency, so I might need to look into better ways of handling that.
There’s still room for improvement though: the thickness of the route lines should ideally scale with the zoom level in screen-space, and the fixed colour of the lines means it’s not always easy to see them depending on the Earth texture being used underneath them, so I might have to look into some kind of contrast/blending setup in the future in order to make the route lines easier to see.
I’ve sporadically but progressively been continuing to work on my Mint interpreter programming language/VM that was heavily based off Robert Nystrom’s excellent Crafting Interpreters Lox language tutorial, and have spent a fair bit of time trying to optimise the main VM bytecode despatch loop among other areas of the VM, as well as performing some benchmark comparisons with other similar bytecode VM interpreter languages like Lua, Python and Ruby to see where Mint stands performance-wise as well as to understand how fast the other VMs are, how they work and some of their performance characteristics for different things.
I managed to speed up the original HashMap implementation a bit by caching the capacity mod bit-mask and the capacity and table load ratio, so as to not recalculate them on-the-fly every lookup which wasn’t needed, and to only update them when the table resized, in addition to adding some compiler hints in order to force inline things and give hints on branch prediction likelihood which helped a bit more.
One of the main bottlenecks in raw execution speed is the main VM stack in terms of operations pushing and popping items onto and off it, so this is really the hot loop of the VM - at least when the Garbage Collector is not being exercised.
On the bytecode opcode execution side of things, I added some new opcodes in order to do some things more efficiently, for example to operate directly on items within the stack in certain limited scenarios when constant values are used, without having to pop and push them back - for example this can be used by compound assignment operators like +=, -=, *=, etc, with constant values being used as the right-hand-side argument, and helped speed things up a bit.
For general for loops incrementing a value by 1 each time, the push/pop overhead was fairly substantial, and I added a dedicated OP_INC_LOCAL opcode to help with this, which can increment the top of the stack by one without popping the stack and then having to push the result after adding 1. The compiler part can detect when this can be used (e.g. in the for loop increment clause, with a constant value being used as the increment) and will use it when possible.
Lua - being a register-based interpreter VM - seems to have an advantage in the area of performance - especially in maths-heavy code - because it doesn’t need to do as many stack operations, and this is one of the reasons Lua is one of the faster bytecode interpreter languages.
The main dispatch loop can also be optimised by using “computed gotos” instead of just a case statement for each opcode within a switch statement: with switch / case statements, compilers are obliged (in C and C++ anyway) to add an upper bound value check, which slows down execution.
In terms of where things stand now performance-wise, I’m fairly happy: Mint is not the fastest interpreter language VM, but it is very competitive against Python 2, Python 3 and Ruby in most cases, and occasionally can win against Lua.
For performance comparisons, I’ve mostly been using basic problem solving exercises from Project Euler which are normally maths-heavy, meaning the benchmark test programs I’m using are slightly skewed benchmarks towards maths operations compared to more general operations (i.e. they don’t generally exercise the Garbage Collector infrastructure), but that’s the type of code execution I’m mostly interested in for the moment.
I’m going to compare Mint against four (I’ll compare Python 2 and Python 3 separately) other interpreter language VMs:
Lua 5.3
Python 2.7
Python 3.8
Ruby 2.7
These are the package versions available with the Linux distro I’m using (Linux Mint) on my laptop, and I’m going to compare them against Mint (VM) built with GCC 9.3, as that’s the system compiler version that I assume the packages for the other interpreter language VMs were compiled with, so seems the fairest compiler to use to compile with. Mint will be built with optimisation level -O3. Normally I like also comparing different compiler versions and optimisation levels, but I’m not going to do that this time as my aim is to compare against other interpreter VMs, and that would increase the number of tests I’d have to do quite a lot, and I’d rather not get into building each one from source, but that would be the fairest way of doing a fully-comprehensive comparison if I had the time.
The tests are being done on a laptop with an Intel i5-8350U processor, with the power plugged in. I’ll make sure the CPU temp is normal before running each test to prevent thermal throttling, and will run five identical tests of each benchmark with each interpreter language, using the mean average as the final result.
I will run the following seven tests:
Test
Description
Test 1
Recursive Fibonacci to 35 levels.
Test 2
The Leibniz algorithm to calculate an approximate value of PI, doing 4,000,000 iterations.
Test 3
Loop value accumulation and mathematical operations: 100,000,000 loops of adding the result of temporary sums and multiplications of the loop control variable. See code examples below.
Test 4
Looped sum of multiples of 3 or 5, up to a value of 50,000,000. A modification of Project Euler exercise 1.
Test 5
A sum of all amicable numbers below 15,000. A modification of Project Euler exercise 21.
Test 6
A count of the number of rectangles in a grid of size (100, 150). A modification of Project Euler exercise 85.
Test 7
A calculation of the sum of all primes up to 10,000,000, using the Sieve of Eratosthenes algorithm.
As quick partial examples, here is the Mint script code for Test 3:
var a = 1;
for (var i = 0; i < 100000000; i += 1)
{
a = (i + i + 3 * 2 + i + 1 - 0.42) / a;
}
print a;
here is the Lua version of Test 3:
local a = 1
for i = 0,100000000-1
do
a = (i + i + 3 * 2 + i + 1 - 0.42) / a;
end
print (a)
here is the Python 3 version:
a = 1
for i in range(0, 100000000):
a = (i + i + 3 * 2 + i + 1 - 0.42) / a
print(a)
and here is the Ruby version:
a = 1
0.upto 100000000-1 do |i|
a = (i + i + 3 * 2 + i + 1 - 0.42) / a
end
print a
print "\n"
These are the results, showing average execution time for each test for all interpreter language VMs (smaller values are better):
Lua has a very good showing (largely I think because it’s a register-based VM instead of a stack-based one), and I’d expect the non-JIT version of LuaJIT which is heavily-optimised on x86-x64 would be even faster.
Mint just wins in Tests 6 and 7, and is second fastest in the remaining tests, which isn’t bad as far as I’m concerned. There’s more room for optimisation - especially with regards to the Garbage Collector which these benchmark tests purposefully didn’t exercise, but also in other areas, i.e. Constant Folding is on my list to look at implementing - but I’m happy enough with the improvements and speed for the moment.
I’ve spent a fair amount of time over the last three months following through the second part of Robert Nystrom’s fantastic Crafting Interpreters free online book, consisting of a complete step-by-step guide to how to “craft” a complete and fully-functional interpreter language virtual machine.
I made an attempt to start two years ago on the tree-walk version, but didn’t have the motivation at the time to complete it (I think the fact I knew the bytecode VM version would be better and more useful/interesting subconsciously made me not bother as much given the bytecode VM version’s chapters were still being written), but I realised just before Christmas that the book had been complete for a few months now, so made a bit of an effort to find time to complete it by writing my version based off the book, as I had a use-case for scripting language embedding in some of my apps that I thought having my own language/VM for could be quite useful/interesting.
I’ve enjoyed the process of following along, learning and writing my own version immensely, and I now have a version - called “Mint” - which is heavily based off the book, but with some subtle language syntax changes and written in C++ instead of C (not sure yet whether that was the best idea in the end, although I hope having a namespace might be useful for embedding in other codebases), and has several additional features over the stock book version of ‘Lox’, for example:
Built-in dictionary/map variable type support for key/value lookups and storage
Support for compound assignment operators (+=, *=, etc)
Array/list slicing / assignment support
break and continue loop-control syntax support
Support for multi-line comments (C/C++-style) and both “#” and “//” single-line comments
Ternary ? operator syntax support.
Example code listings, demonstrating fizzbuzz:
// fizzbuzz
for (var i = 1; i <= 100; i += 1)
{
if (i % 15 == 0)
print "fizzbuzz";
else if (i % 3 == 0)
print "fizz";
else if (i % 5 == 0)
print "buzz";
else
print i;
}
Calculating the approximate value of PI:
# calculate PI with the Leibniz algorithm...
def calculatePI(iterations)
{
var x = 1.0;
var pi = 1.0;
for (var i = 2; i < iterations + 2; i += 1)
{
x *= -1.0;
pi += x / (2.0 * i - 1.0);
}
pi *= 4.0;
return pi;
}
var piVal = calculatePI(40000000);
print "PI: " + toStr(piVal);
producing:
PI: 3.14159266192262
and a fully-functional Mint Class, which can convert Roman numeral strings to numbers and vice versa, downloadable here
I’m going to continue developing it in the background, in order to attempt to integrate it into several of my applications, and also try and optimise its performance a bit and see how it compares to other interpreter languages.
For close to two years now I’ve been developing my own webserver, partly to re-learn about HTTP and web technology that I haven’t really been following too closely for over eight years, and therefore my knowledge of that area has atrophied, but also to be able to have a stand-alone webserver that I control and can customise to my needs within one stand-alone codebase, rather than having to use multiple technology stacks, which from my point-of-view is a huge benefit (much less configuration and things to learn/remember). My main use-case for having a webserver is developing my own photo gallery with photos described in various ways (by date, geographical location hierarchy, tags, camera type, etc) which off-the-shelf/available solutions don’t provide to the degree I want.
I’ve now got a solution which supports HTTP 1.1 fairly robustly that I’m relatively happy with from a C++ technology perspective, although the JavaScript/HTML/CSS parts - of which I’m not very experienced - are pretty basic and likely less-than-ideal in terms of good practice and the best ways of doing things.
For hosting things on the public web, HTTPS support is generally a very good idea these days, and given there’s authentication / password functionality for my photo gallery, having HTTPS support is critical to prevent sniffing HTTP headers (among other security risks). Generally, it’s not the ideal situation to
put a self-created webserver on the public internet directly with public ports open: it would better practice to put it behind a well-known and reliable web/proxy server like nginx or Apache - however I was curious what would be involved in implementing HTTPS secure socket functionality at both the HTTPS / TLS and TCP levels, so decided to start implementing HTTPS support a few months ago.
At first I had intended to go with OpenSSL directly, however a bit of research seemed to indicate that might not be the best solution given the complexity and breadth of OpenSSL’s functionality, and therefore the possibility of making mistakes with utilising it would be greater, leading to more potential bugs.
There were a few options I could have taken, although some of the software licenses did not entirely match my ideal choices in that area, but in the end I decided to use AWS’s s2n. It’s a minimal open-source TLS implementation, although it does rely on other libraries (i.e. OpenSSL, but it can support others) for the cipher side of things - but it’s simple to use, and seems to have sensible defaults.
Implementation wasn’t too difficult, although generating certificates for localhost is annoying for testing, and not all web browsers were happy with them (Chrome refused to accept them, but Firefox did). It’s also a lot more troublesome to debug what’s going on at the TCP/HTTP level, as you can’t as trivially connect WireShark and sniff what’s going on at the packet level (but that’s the whole point!).
So my webserver (creatively called ‘WebServe’) now supports both HTTP and HTTPS connections, the latter with certificates authenticating the connection, theoretically allowing perfectly secure connections between the web browser and the webserver. It seems to work perfectly with Firefox and Chrome on Linux and MacOS, however very occasionally Safari on iOS (but not MacOS) fails to download an image when keep-alive is enabled, so it’s possible there’s some subtle bug somewhere still.
A year ago I started writing a new basic app (Sniffle) to find log files based off directory/filepath patterns, allowing for recursive directory pattern wildcard matching, and then performing file content operations on the found files, mainly involving grepping/counting items, with an emphasis on finding files on NFS networks. Existing applications like grep, ack and ag (amongst others) do provide existing functionality for some of the use cases, but their defaults are generally wrong for my use-cases (i.e. I want symlinks to always be followed, and to do recursive searching by default), and some of the methods they use to be fast are not always directly compatible (at least efficiently) with NFS networks (i.e. mmap-ing files for better content searching performance).
The number of logs I’d want to search through was often in the tens of thousands, and some of the logs are (unfortunately, and often needlessly) very verbose and can be > 5 MB in some cases. Using a log database or some other similar infrastructure would generally be the more principled way of solving this issue at scale, but I’m generally the only person who occasionally needs to perform these searches, so getting dedicated infrastructure (i.e. a database) for this use-case from IT was very unlikely, essentially meaning I ended up writing my own solution at home in my own time for use at work.
I’ve had working support for finding files, grepping through those files, counting string matches in files and finding multiple cascading strings (optionally in particular orders - i.e. if the first one isn’t found, there’s no point looking for any of the others) for a while now, as well as the ability to filter the list of found files to grep/process first by modified date (e.g. log files last modified within the past 5 days) or file size threshold, but a new use-case came up at work recently where I wanted to look for time period gaps in the log timestamps, indicating that the process writing the logs (a renderer) either hadn’t been doing anything for a while, or had taken longer than expected to do some task.
Checking the time delta between timestamps on consecutive lines in a file is pretty trivial to implement at a conceptual level, however doing so in a way which is performant is a bit more work: naively using strptime() to parse the time has a significant and noticeable overhead, due to internal use of mktime() which is very expensive, and even using sscanf() to pull out the constituent parts and rebuild them, or using a series of atoi() calls - while noticeably faster than strptime() - can be improved upon if you’re just extracting digit components in known positions (although supporting multiple date-formats complicates this slightly).
Given a fixed and valid timestamp string with consistent width zero-padding - which I could validate and guarantee in my use-case - I ended up settling on subtracting each string character value per timestamp unit digit by the char value '0', to give the 0-based 0-9 integer value, and then multiplying it by its digit position in the component number and adding these values together grouped by component number, effectively extracting and accumulating final values very quickly.
It’s somewhat hacky and verbose, but demonstrably faster than the more normal approaches mentioned above, which for my purposes made it a worthwhile optimisation.
As an example, given a std::string currentString; representing a non-empty log line which is guaranteed to have at least the minimum number of string characters for an ISO 8601 date/time stamp, and size_t timestampStart representing the character position offset within the string where the timestamp starts (in order to support varying formatting around the timestamp), with the start of a log line looking something like this:
[2019-03-22 09:42:13] Did something useful
then code to parse the year from the string looks like this:
and handling the time components is done similarly with appropriate position indices.
Using these component integer values to represent a full time value is now context-dependent on what’s trying to be achieved: if you just wanted to sort the timestamps, you could just accumulate the numbers, multiplying each component by a component-respective multiplier to build the number of seconds, i.e.:
In other words, using a constant of 31 for the number of days in all months: because we’d only care about relative positions based on numbers for sorting, and not absolute deltas, it wouldn’t be necessary to use the correct number of days in the month.
However, for the use-case of working out time durations between each log timestamp, absolute delta values are required, and this does involve knowing the number of days within each month - so that you accurately know the difference between 23:55 on the last day of a month is 10 minutes before 00:05 on the first day of the month, which makes things a bit more complicated. I ended up using two pre-calculated static const arrays of the months,
one for non-leap year years, the other for leap year years, i.e.:
// pre-calculated totals for numbers of days from start of year for each month
static const unsigned int kCumulativeDaysInYearForMonth[12] = { 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334 };
static const unsigned int kCumulativeDaysInYearForMonthLeapYear[12] = { 0, 31, 60, 91, 121, 152, 182, 213, 244, 274, 305, 335 };
and then working out whether the year was a leap year by cheating a bit and only checking the first timestamp on the first line of the logfile to see if it was a leap year, and then caching that in a variable for the rest of the log processing:
which then meant not needing to do any branching for any of the remainder log line timestamps to work this out, and being able to build up the number of seconds
a timestamp represented with:
which then works to provide exact absolute counts of the number of seconds the timestamp represents for nearly all situations, except for two:
The first line of the log file having a timestamp almost two months before the end of February, e.g. December 30th, and some following log line timestamps in the same log file then progressing on to the end of February, potentially meaning there was a discrepancy between the code thinking the year was a leap year or not
Daylight Savings Time changes
Both of these situations in the end I decided to ignore: the first one because it was a total non-issue for my use-case, as if the length of the log files timestamps stretched to almost two months, straddling a new year and then on to the end of February, there would be much bigger issues to worry about: almost all log files should have had a duration of under 48 hours, and anything over two weeks long would be a pathological situation.
For the Daylight Savings Time change, while it was a definite potential issue that could happen - either adding an extra hour or removing it from the time value in the hour after the change - which could then have tripped or not tripped the time delta threshold logic incorrectly, I was happy to let that problem slide: dealing with DST changes in computer systems is almost always problematic in my experience (especially if using local timestamps like here), and while it was technically solvable if you know the dates it changes (per geographic location: different countries change at differing times during the year, and the Earth hemisphere matters as well for direction), I just didn’t feel it was worth it for the potential of some false positives/negatives happening within two to three hours per year.
I have recently been trying to change Imagine’s Acceleration Structure infrastructure to be more dynamic, allowing different objects and geometry instances to have different acceleration structures either automatically based on heuristics, or based on user-specification within the interface.
Imagine’s acceleration structures have for the past two years been implemented with the Curiously Recurring Template design pattern, which allows virtual function-like ability to some extent while enabling the compiler to inline the functions. I chose this way of doing things as I had assumed that Virtual Functions would have some overhead, despite previously doing some experimentation with Virtual Functions and surprisingly finding they don’t seem to have any overhead compared to fully-inline-able functions.
The “Curiously Recurring Template” pattern doesn’t easily allow a templated base class (for Triangles, Shapes or Objects in Imagine’s case) to be specified as a pointer and then the actual implementation to be instantiated as a derived templated acceleration structure, which is what I needed for this dynamic flexibility.
So I decided to do some more benchmarks to investigate any overhead again.
First of all, I tried a synthetic benchmark of just a simple for loop of 1,073,741,824 iterations, calling getHitObject() on the acceleration structure pointer. For the “Curiously Recurring Template” implementation, the pointer type was of KDTreeVolume<T>, the actual derived class and the object allocated for that pointer was of the same type.
In the Virtual Function implementation, the pointer type was to AccelerationStructure<T>, the base class and the actual object allocated for the pointer was KDTree<T>, a duplicate of the KDTreeVolume<T> class but which used standard C++ virtual inheritance from the abstract AccelerationStructure<T> base class.
The code was run in a single thread.
Eight pairs of runs were done, alternating each implementation, and I tried to make sure the CPU core temperatures were under 55 degC before starting each test to ensure that there was no disadvantage to be had by a core not being able to Turbo Boost overclock.
Test Run
CRT
Virtual Function
1
138.73941
137.11993
2
141.10697
137.10513
3
136.96121
137.07798
4
136.67388
139.22481
5
136.91679
138.22481
6
137.20460
138.49725
7
138.77106
139.43341
8
136.85819
137.13652
Mean Average
137.90402
137.97748
Other than the first two results for the “Curiously Recurring Template” implementation, the Virtual Function method seems very slightly slower, but this difference is within the margin of error. This surprised me, but given the simple test case, it’s possible that the processor’s branch-predictor was negating the overhead of the v-table lookup, and thus might not be showing the difference.
So I decided to do some more realistic general purpose rendering benchmarks with the two different implementations, to see if any difference could be spotted there.
I created a scene with a fully-enclosed room, with 32 cubes inside and 2 area lights, and all surfaces fully diffuse. All geometry objects had less than or equal to 12 triangles, so the acceleration structures would be very shallow and thus any Virtual Function overhead would not be dwarfed by the work each function was doing on the acceleration structure.
The first test was at 1024x768, with 256 samples per pixel, and 10 ray bounces.
With this test, the getHitObject() function would be called 2,013,265,920 times (for each camera ray and each diffuse bounce ray) and the doesOcclude() function would be called 4,026,531,840 times, once for each light (no light importance sampling was used) for each surface evaluation. All threads were being used for rendering.
Test Run
CRT
Virtual Functions
1
05:52.720
05:41.340
2
05:53.420
05:40.790
3
05:51.870
05:41.620
4
05:49.580
05:42.200
5
05:46.380
05:41.790
6
05:49.150
05:44.380
Average
05:50.520
05:42.020
The above results are in minutes, and show that the Virtual Function implementation was consistently slightly faster. I decided to do these tests again with double the number of samples per pixel (to double the above numbers), and again the results were pretty much the same:
Test Run
CRT
Virtual Functions
1
11:41.970
11:40.880
2
11:41.380
11:37.710
3
11:47.790
11:31.560
4
11:37.530
11:26.680
5
11:45.270
11:31.530
Average
11:42.788
11:33.672
I’m still surprised by this, but I’m putting it down to either compilers being a lot more clever than they used to, or the inlined “Curiously Recurring Template” implementation creating bloated instruction size. Or more likely, the fact that things like cache misses, load dependencies and branch miss-predictions within triangle and boundary box ray intersection code hide any overhead there may be.
Regardless, it appears that to all intents and purposes in my use-case, Virtual Function overhead is practically non-existent. I’m sure things would change with deeper inheritance hierarchies and multiple inheritance, but at least in my use-case it seems safe to move back to Virtual Functions. What’s more, Intel’s Embree high-performance ray tracing kernels use Virtual Functions, and they’re pretty-much state-of-the-art.