This month I bought and received a new Apple MacBook Pro (M2 Pro, 14-inch, 2023) with the aim of replacing my own Apple MacBook Pro 15-inch (Intel) 2015 model which I bought in 2016. The MacBook Pro 15 still does work, but the battery life is awful now (I could have it replaced, which I’ve done several times with laptops in the past), the internal fans barely work, and the rubber around the screen is disintegrating, so with a trip back to the Northern Hemisphere planned next month, I thought it was time for a replacement.
A year ago I was provided (on loan) a work-provided MacBook Pro 14 M1 Pro (see previous benchmarks) which I’ve been using a bit, so I knew mostly what to expect in terms of performance and from the laptop in general, but I was curious to compare the performance of the M2 Pro against the M1 Pro (and the old Intel machine).
It’s not going to be a completely fair apples-to-apples comparison, as the work-provided MacBook Pro 14 M1 Pro processor is the 10-core version which has two extra performance cores than the baseline did - having eight performance cores and two efficiency cores - and the M2 Pro I’ve just bought is the baseline model - with six performance cores and four efficiency cores - but it should provide a rough indication of what performance to expect.
The Xcode / Apple Clang compiler versions are also different: My MacBook Pro 15 (Intel) is still running quite an old MacOS version, with an older compiler which I don’t want to update, and while I did install Xcode 14.3 on the 2021 MacBook Pro M1 Pro (as well as the command line tools) in order to attempt to match what I’d just installed on my new 2023 MacBook Pro M2 Pro, clang --version still shows version 13.1.6, whereas my new 2023 M2 Pro MacBook Pro shows 14.0.3 being used, so I’m not really sure what’s going on there, as Xcode -> About Xcode shows Version 14.3.1 as I’d expect on both MacBook Pro 14 machines (and both have the command line tools for that version of Xcode installed).
The MacBook Pro 14s are both running MacOS Ventura 13.4.
Tests:
Copying what I did in the test last year, I’ll be using two of my apps as benchmarks: my Mint interpreter language VM (originally based off Robert Nystrom’s excellent Crafting Interpreters Lox language tutorial) but with additional functionality and performance improvements, which I’ll use to benchmark two Mint scripts as single-threaded tests, and also my Imagine pathtracing renderer, which has native SSE intrinsics support for Intel and native Neon intrinsics support for ARM, which I’ll run in both single- and multi-threaded scenarios.
Both apps will be compiled with -march=native on the Intel side and -mcpu=native on the Apple Silicon / ARM side, using the clang version on the machine in question, as well as optimisation level: -O3.
The two Mint script tests will be loop value calculation as Test 1:
var a = 1;
for (var i = 0; i < 100000000; i += 1)
{
a = (i + i + 3 * 2 + i + 1 - 0.42) / a;
}
print a;
and a variation of Project Euler 21 to calculate the sum of all Amicable numbers under 15,000 as Test 2.
The Imagine rendering tests will render three different scenes in both single- and multi-threaded mode.
The first render will be the same maze scene with spherical area lights that I used in the test last year (example image above), but with different settings:
resolution will be 256 x 256, 256 samples-per-pixel will be used, but this time only one next-event light sample will be taken each path vertex.
The general ray traversal and ray intersection will utilise SIMD, but the (fairly expensive) perfect light sphere sampling is scalar, and very unlikely
to be vectorised by the compilers themselves.
The second render will be a 450 x 338 resolution render of a Signed Distance Field primitive of a Julia Fractal (example image above, although with different settings), which is quite expensive to evaluate,
and also does not have any SIMD utilisation for the SDF evaluation / intersection. There’s a physical Sky IBL in the scene as a light, and 144 samples-per-pixel will be used, with 3x3 Blackman Harris pixel filtering being used.
The third render will be a 450 x 338 resolution render of 2,326,299 instanced mesh cubes in the (pre-calculated) shape of a Julia Fractal, which will
fully-utilise SIMD instructions for ray traversal in the BVH and for ray / primitive intersections. Again, there’s a physical Sky IBL in the scene,
144 samples-per-pixel will be used, but this time no pixel reconstruction filtering will be used (so effectively Box 1x1).
These tests will all be done on (close to fully-charged) battery power - I discovered in the tests last year that Apple doesn’t seem to down-clock on battery power - and I will also wait between test runs for the processor temperatures to be below 50 degC before running the next test, to try and reduce the impact of thermal throttling.
All tests will be run three times, and results below will show the mean average of those numbers.
Results
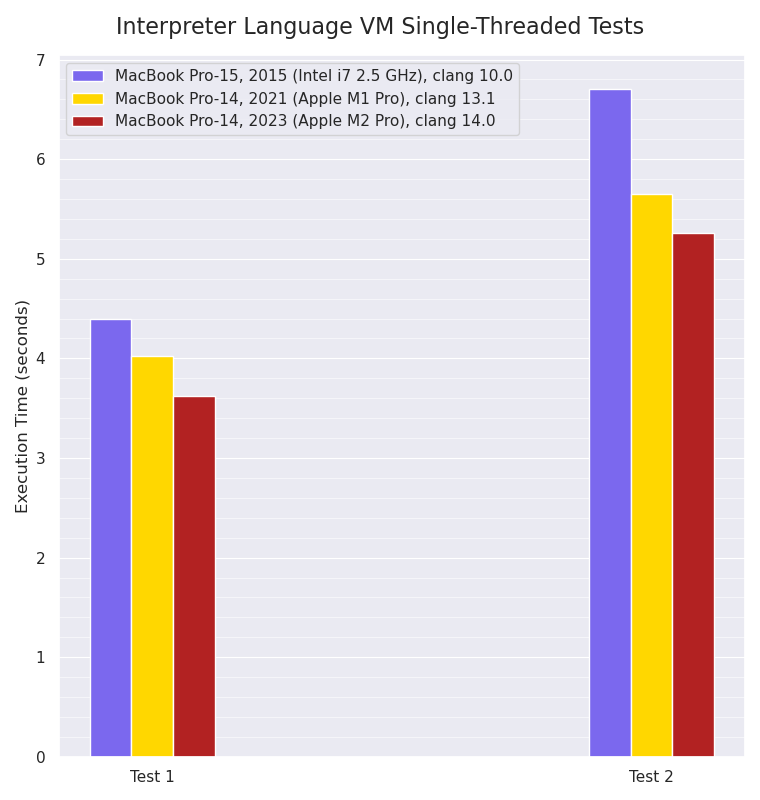
Single-threaded Mint VM interpreter:
Single-threaded Mint interpreter VM benchmarks, smaller values are better:
For these single-threaded tests, the M2 Pro has a small improvement over the M1 Pro’s performance, which itself is around 10-16% faster than the eight year old Intel i7 processor. As mentioned last year however, I think this is very likely because the Mint VM execution is often branch-prediction constrained within the main VM bytecode interpreter loop, so there’s a limit to the amount of Instruction-Level Parallelism that’s achievable from the eight-wide M1 Pro and M2 Pro.
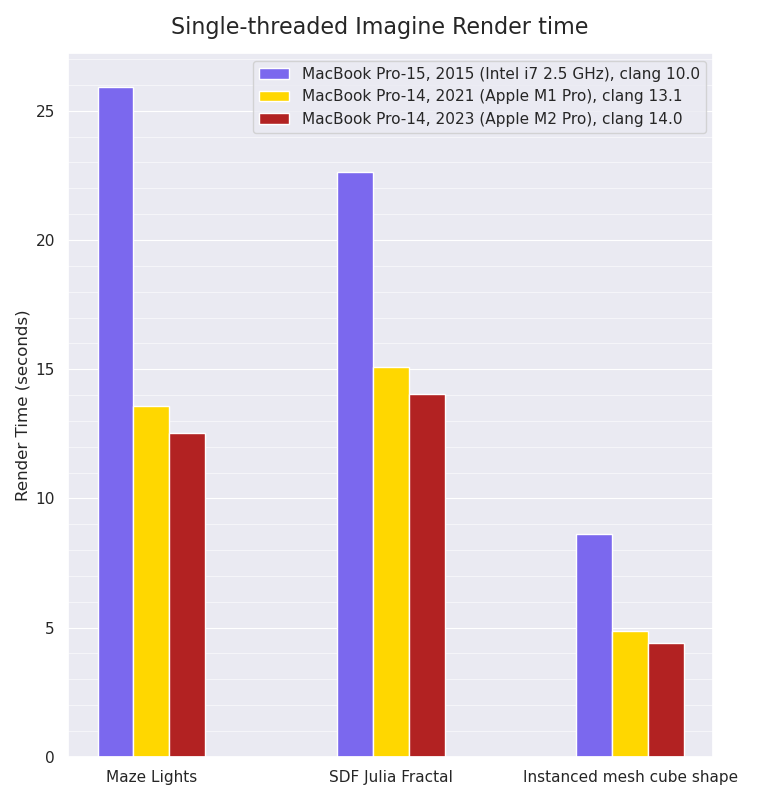
Single-threaded Imagine rendering:
Single-threaded Imagine rendering benchmarks, smaller values are better:
The single-threaded rendering tests, which have a lot more floating point calculations and SIMD usage, show a small performance improvement for the M2 Pro over the M1 Pro. Intriguingly, the Maze Lights scene is the test with the biggest performance increase (almost 2x faster) from the Intel machine to the Apple M1 Pro: the other tests show slightly smaller gains, which I wouldn’t have expected. Without further microbenchmarks of various isolated parts of those tests, it’s difficult to guess why that might be, but the different render tests do exercise different calculations and code paths.
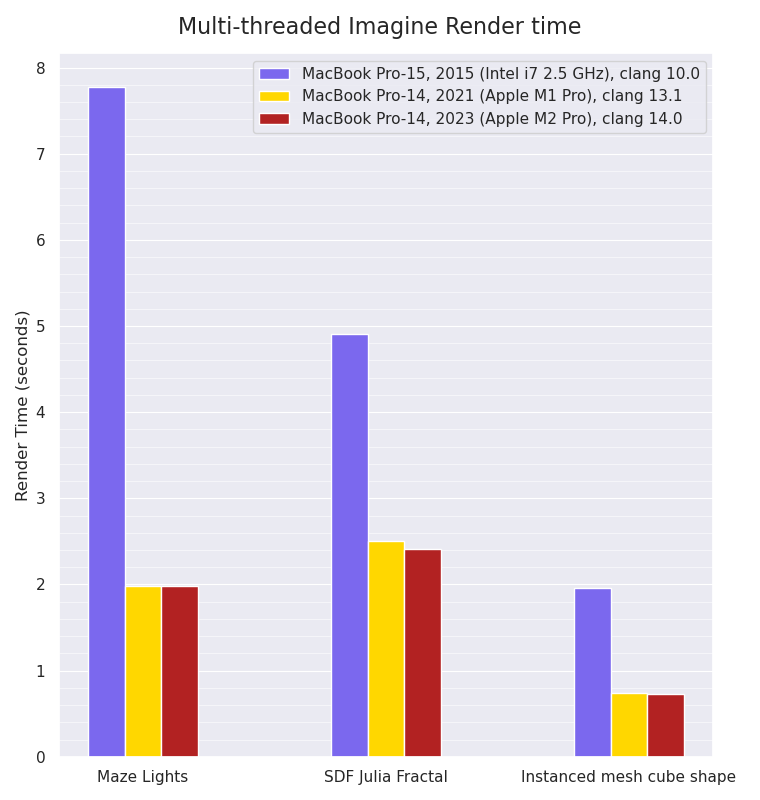
Multi-threaded Imagine rendering:
Multi-threaded Imagine rendering benchmarks, smaller values are better:
The multi-threaded rendering tests show that due to the fact the M1 Pro machine has eight performance cores and two efficiency cores, whilst the M2 Pro
machine only has six performance cores and four efficiency cores, the M2 Pro machine is only very slightly faster in the SDF Julia Fractal render scene than the M1 Pro machine, and ties in the other two tests. Once again, the Maze Lights scene shows the biggest performance increase - almost 4x faster - from the Intel CPU to the Apple Silicon ones, with the other two tests showing a less dramatic difference (between 2x to 3x faster).
Conclusion
I think a not too bad showing for the baseline model: the M2 Pro can beat the M1 Pro by a small margin in all single-threaded tests, and can either just about equal or slightly beat the M1 Pro which has more performance cores (but two less efficiency cores) in the multi-threaded tests.
Last week I received a work-provided (on loan) new Apple MacBook Pro (14-inch, 2021) with the Apple M1 Pro 10-core processor, so I was very curious to see how it performed with some of my code, given the generally excellent reviews and reports I’d seen by people with it online.
I have my own MacBook Pro 15-inch 2015 (Intel i7) model which I’ll be comparing it against as a basic benchmark performance test, although it won’t be a completely fair test as the two machines are running different versions of MacOS and the clang compiler, and I didn’t want to upgrade my own machine’s MacOS version to a newer version (for various reasons). So the code being executed on the different machines will be generated by different versions of clang, but given the micro-architecture is totally different anyway, I think it’s still a meaningful test and at least will show the performance difference between the two laptops.
My old MacBook Pro 15-inch 2015 is a 2.5 GHz Intel Core i7, with four cores, eight threads, and 1600 Mhz DDR3 memory, running macOS 10.14.5 (Mojave), with Xcode 10.2.1 installed which has clang version 10.0.1.
The new MacBook Pro 14-inch 2021 is the M1 Pro 10-core version, with 8 performance cores and 2 efficiency cores, running macOS 12.3 (Monterey), with Xcode 13.4.1 installed which has clang version 13.1.6.
Tests:
I’ll be using two of my apps as benchmarks: my Mint interpreter language VM (originally based off Robert Nystrom’s excellent Crafting Interpreters Lox language tutorial) but with additional functionality and performance improvements, which I’ll use to benchmark two Mint scripts as single-threaded tests, and also my Imagine pathtracing renderer, which has native SSE intrinsics support for Intel and native Neon intrinsics support for ARM, which I’ll run in both single- and multi-threaded scenarios.
Both apps will be compiled with -march=native on the Intel side and -mcpu=native on the Apple M1 Pro ARM side, using the clang version on the machine in question, as well as optimisation level: -O3.
The two Mint script tests will be loop value calculation as Test 1:
var a = 1;
for (var i = 0; i < 100000000; i += 1)
{
a = (i + i + 3 * 2 + i + 1 - 0.42) / a;
}
print a;
and a variation of Project Euler 21 to calculate the sum of all Amicable numbers under 15,000 as Test 2.
The Imagine rendering tests will render the below example scene of a basic maze with 12 spherical area lights and one hemisphere light, with four Next Event Estimation samples being taken each bounce to evaluate the lighting, and using Cone sampling to perfectly sample each spherical area light from each hitpoint, with 256 samples-per-pixel being done, using stratified sampling and a ray depth of 6 diffuse bounces. Depending on the setup of the tests (single-threaded, multi-threaded, etc), I’ll render the scene at resolutions of: 150 x 150, 300 x 300 and 600 x 600.
For all tests, I’ll run them on battery power and then mains power, in case that affects the clocking of the processors, and will also wait between test runs for the processor temperatures to be below 50 degC before running the next test, to try and reduce the impact of thermal throttling. However, for the longer-running multi-threaded Imagine rendering tests I’m fairly sure thermal throttling will start to take place on the Intel 2015 machine given how fast the fans start to spin in longer-running scenarios.
All tests will be run three times, and results below will show the mean average of those numbers.
Results
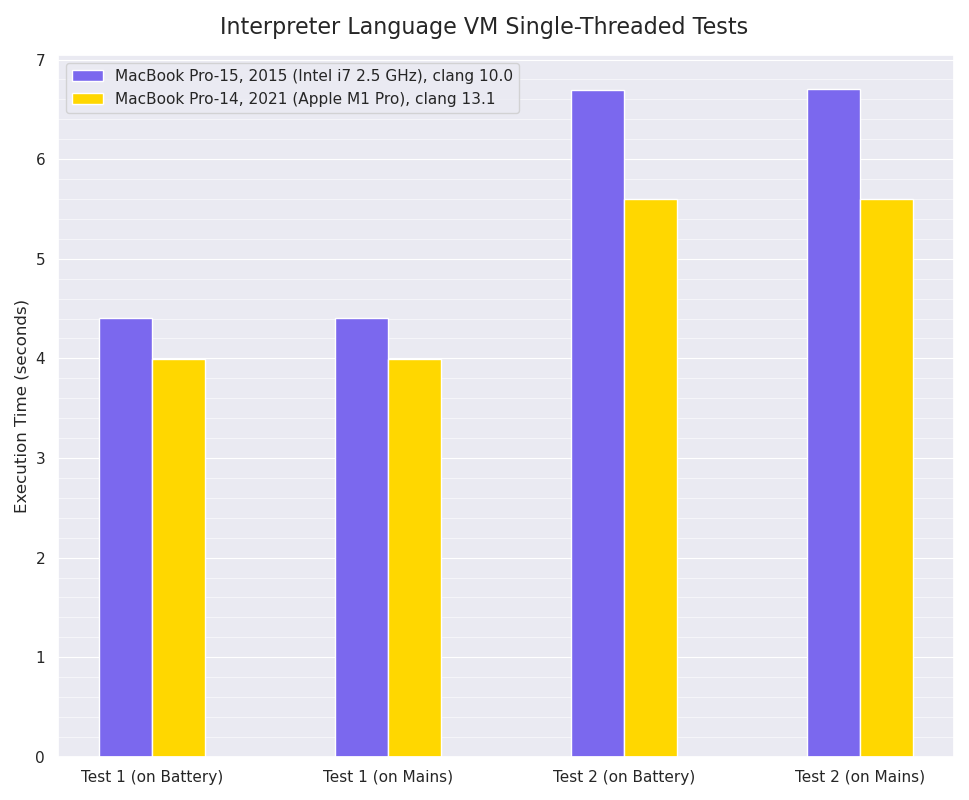
Single-threaded Mint VM interpreter:
Single-threaded Mint interpreter VM benchmarks, smaller values are better:
For these single-threaded tests, the M1 Pro has fairly modest (~11% faster in Test 1, ~16% faster in Test 2) improvements over the seven year old Intel i7, however as the Mint VM execution is often branch-prediction constrained within the main VM bytecode interpreter loop, I expect this doesn’t really allow the M1 Pro’s eight-wide design to really stretch its legs running these benchmarks, as there’s a limit to the amount of Instruction-Level Parallelism that’s achievable.
It’s interesting to see that there’s no apparent difference in performance between running on battery vs running connected to the mains: I was expecting to see a difference - even if only on the Intel i7 MBP - as I know my Thinkpad T480s running Linux shows significant performance differences between the two states, but Apple clearly don’t seem to be implementing that strategy.
Single-threaded Imagine rendering:
Single-threaded Imagine rendering benchmarks, smaller values are better:
Things start to look more impressive for the M1 Pro in the single-threaded rendering tests, as here there are a lot more floating point calculations being done with a lot less branching, and there’s a fair amount of SIMD use (i.e. ray intersection / traversal code, which uses native SSE or Neon instructions for the respective platform architectures) allowing the M1 Pro to show what it can do.
For both the 150 x 150 resolution and 300 x 300 resolution renders, the M1 Pro machine completed the tasks in ~46% less time, so it’s close to twice as fast as the older Intel machine. Again, there was no apparent performance difference between running powered off the battery compared to running with the machines plugged into the mains power.
Multi-threaded Imagine rendering:
Multi-threaded Imagine rendering benchmarks, smaller values are better:
The multi-threaded rendering tests show that for the shorter-duration 300 x 300 resolution render, the M1 Pro was more than three times faster (render time was less than a 1/3 of the Intel MBP’s i7 render time), and for the longer-duration 600 x 600 resolution render this ratio was slightly better still - I suspect because of the fact the Apple M1 Pro has significantly better thermal performance than the Intel i7, so is not throttling as much - if at all - although watching the temps on the M1 Pro machine towards the end of the test shows it did reach 84 degC, so it’s possible throttling is happening a bit.
Conclusion
So for most code that’s likely not branch/dependency-bound, it would seem the almost one year-old M1 Pro being tested here is around three times faster than the seven year-old Intel i7 model (although the base M1 Pro model with two less performance cores will not be as fast), and for multi-threaded code that parallelises well it can be more than three times faster, with much better thermal performance (which means less fan noise) and battery life, which is exactly what you’d want from a laptop, and I think shows that the Apple M1 processors are something to be excited about.
I’ve sporadically but progressively been continuing to work on my Mint interpreter programming language/VM that was heavily based off Robert Nystrom’s excellent Crafting Interpreters Lox language tutorial, and have spent a fair bit of time trying to optimise the main VM bytecode despatch loop among other areas of the VM, as well as performing some benchmark comparisons with other similar bytecode VM interpreter languages like Lua, Python and Ruby to see where Mint stands performance-wise as well as to understand how fast the other VMs are, how they work and some of their performance characteristics for different things.
I managed to speed up the original HashMap implementation a bit by caching the capacity mod bit-mask and the capacity and table load ratio, so as to not recalculate them on-the-fly every lookup which wasn’t needed, and to only update them when the table resized, in addition to adding some compiler hints in order to force inline things and give hints on branch prediction likelihood which helped a bit more.
One of the main bottlenecks in raw execution speed is the main VM stack in terms of operations pushing and popping items onto and off it, so this is really the hot loop of the VM - at least when the Garbage Collector is not being exercised.
On the bytecode opcode execution side of things, I added some new opcodes in order to do some things more efficiently, for example to operate directly on items within the stack in certain limited scenarios when constant values are used, without having to pop and push them back - for example this can be used by compound assignment operators like +=, -=, *=, etc, with constant values being used as the right-hand-side argument, and helped speed things up a bit.
For general for loops incrementing a value by 1 each time, the push/pop overhead was fairly substantial, and I added a dedicated OP_INC_LOCAL opcode to help with this, which can increment the top of the stack by one without popping the stack and then having to push the result after adding 1. The compiler part can detect when this can be used (e.g. in the for loop increment clause, with a constant value being used as the increment) and will use it when possible.
Lua - being a register-based interpreter VM - seems to have an advantage in the area of performance - especially in maths-heavy code - because it doesn’t need to do as many stack operations, and this is one of the reasons Lua is one of the faster bytecode interpreter languages.
The main dispatch loop can also be optimised by using “computed gotos” instead of just a case statement for each opcode within a switch statement: with switch / case statements, compilers are obliged (in C and C++ anyway) to add an upper bound value check, which slows down execution.
In terms of where things stand now performance-wise, I’m fairly happy: Mint is not the fastest interpreter language VM, but it is very competitive against Python 2, Python 3 and Ruby in most cases, and occasionally can win against Lua.
For performance comparisons, I’ve mostly been using basic problem solving exercises from Project Euler which are normally maths-heavy, meaning the benchmark test programs I’m using are slightly skewed benchmarks towards maths operations compared to more general operations (i.e. they don’t generally exercise the Garbage Collector infrastructure), but that’s the type of code execution I’m mostly interested in for the moment.
I’m going to compare Mint against four (I’ll compare Python 2 and Python 3 separately) other interpreter language VMs:
Lua 5.3
Python 2.7
Python 3.8
Ruby 2.7
These are the package versions available with the Linux distro I’m using (Linux Mint) on my laptop, and I’m going to compare them against Mint (VM) built with GCC 9.3, as that’s the system compiler version that I assume the packages for the other interpreter language VMs were compiled with, so seems the fairest compiler to use to compile with. Mint will be built with optimisation level -O3. Normally I like also comparing different compiler versions and optimisation levels, but I’m not going to do that this time as my aim is to compare against other interpreter VMs, and that would increase the number of tests I’d have to do quite a lot, and I’d rather not get into building each one from source, but that would be the fairest way of doing a fully-comprehensive comparison if I had the time.
The tests are being done on a laptop with an Intel i5-8350U processor, with the power plugged in. I’ll make sure the CPU temp is normal before running each test to prevent thermal throttling, and will run five identical tests of each benchmark with each interpreter language, using the mean average as the final result.
I will run the following seven tests:
Test
Description
Test 1
Recursive Fibonacci to 35 levels.
Test 2
The Leibniz algorithm to calculate an approximate value of PI, doing 4,000,000 iterations.
Test 3
Loop value accumulation and mathematical operations: 100,000,000 loops of adding the result of temporary sums and multiplications of the loop control variable. See code examples below.
Test 4
Looped sum of multiples of 3 or 5, up to a value of 50,000,000. A modification of Project Euler exercise 1.
Test 5
A sum of all amicable numbers below 15,000. A modification of Project Euler exercise 21.
Test 6
A count of the number of rectangles in a grid of size (100, 150). A modification of Project Euler exercise 85.
Test 7
A calculation of the sum of all primes up to 10,000,000, using the Sieve of Eratosthenes algorithm.
As quick partial examples, here is the Mint script code for Test 3:
var a = 1;
for (var i = 0; i < 100000000; i += 1)
{
a = (i + i + 3 * 2 + i + 1 - 0.42) / a;
}
print a;
here is the Lua version of Test 3:
local a = 1
for i = 0,100000000-1
do
a = (i + i + 3 * 2 + i + 1 - 0.42) / a;
end
print (a)
here is the Python 3 version:
a = 1
for i in range(0, 100000000):
a = (i + i + 3 * 2 + i + 1 - 0.42) / a
print(a)
and here is the Ruby version:
a = 1
0.upto 100000000-1 do |i|
a = (i + i + 3 * 2 + i + 1 - 0.42) / a
end
print a
print "\n"
These are the results, showing average execution time for each test for all interpreter language VMs (smaller values are better):
Lua has a very good showing (largely I think because it’s a register-based VM instead of a stack-based one), and I’d expect the non-JIT version of LuaJIT which is heavily-optimised on x86-x64 would be even faster.
Mint just wins in Tests 6 and 7, and is second fastest in the remaining tests, which isn’t bad as far as I’m concerned. There’s more room for optimisation - especially with regards to the Garbage Collector which these benchmark tests purposefully didn’t exercise, but also in other areas, i.e. Constant Folding is on my list to look at implementing - but I’m happy enough with the improvements and speed for the moment.